
计算机组成原理(五)——中央处理器
CPU组成与功能






数据通路与总线系统结构
















总线结构与CPU指令周期









硬布线控制器设计









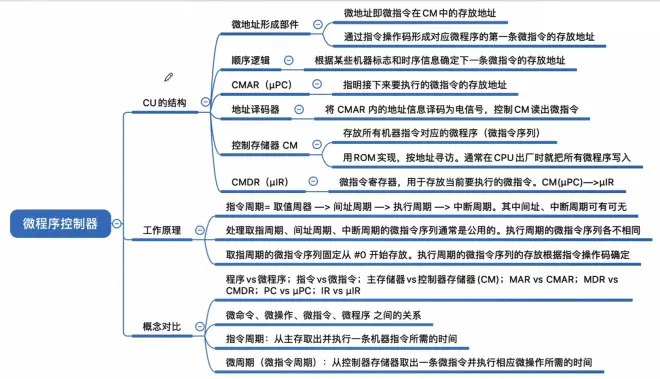
微程序控制器








微程序设计


微指令格式












单周期MIPS CPU



多周期MIPS CPU数据通路

习题












快速面经
Q: 写入存储系统的粒度太大,会不会导致数据原子性问题?例如一次性写100MB,如果系统突然crash,会不会只有一部分数据持久化了,另一部分丢失了?如果要解决原子性问题,一般会设计什么机制?
A: 如果写入存储系统的粒度太大,会导致数据原子性问题。为了解决这个问题,一般会采用分布式事务机制,即将一次性写入的数据分割成多个小块,每个小块都要经过一系列的事务操作,确保每个小块的数据都能够持久化,从而保证数据的原子性。
Q: 在从应用程序到存储介质的链路上,无论读还是写,数据可能要被拷贝好几次,这几次拷贝能不能去掉?如果我们去掉大部分拷贝操作,会有什么副作用,要怎么缓解副作用?
是的,可以通过使用直接访问技术来减少数据拷贝次数。例如,可以使用内存映射文件(MMF)技术,将应用程序的内存直接映射到存储介质,从而避免数据拷贝。但是,这种技术也会带来一些副作用,例如安全性问题和性能问题。为了缓解这些副作用,可以使用安全机制,如加密和访问控制,来保护数据安全,并使用缓存技术来提高性能。
Q: 一个关系型数据库大概率是会被并发访问的,如果要保证并发安全,除了在行数据上加悲观锁还有其他方式吗?
除了悲观锁之外,还可以使用乐观锁来保证并发安全。乐观锁通过在每次更新操作前检查数据的版本号来实现,如果版本号不匹配,则拒绝更新操作,从而避免数据的不一致性。此外,还可以使用分布式锁来保证并发安全,它可以通过在多个节点上同步锁定数据来实现。
Q: 在数据库领域,把数据按行存和按列存各有好处,你能从性能优先的角度设计出一种混合存储格式吗?
可以设计出一种混合存储格式,它可以将数据按行存储和按列存储相结合,以提高性能。例如,可以将数据按行存储在内存中,而将数据按列存储在磁盘上,以便更快地访问和更新数据。此外,可以使用索引来提高查询性能,并使用缓存来减少磁盘访问次数。
Q: WAL 日志到底是如何保证数据的持久化,宕机后数据不丢失的?相比于其他方案,WAL 日志都有什么优势?
WAL就像日志中心一样,它被同一个region server中的所有region共享。当客户端启动一个操作来修改数据,该操作便会被封装成一个KeyValue对象实例中,并通过RPC调用发送出去。这些调用成批的发送给含有匹配region的HRegionServer。一旦KeyValue到达,它们会被发送到管理相应行的HRegion对象实例。数据便被写入到WAL,然后放入到实际拥有记录的存储文件的MemStore中。最后当memstore达到一定的大小或者经历一个特定时间之后,数据就会异步地连续写入到文件系统中。在写入的过程中,数据以一种不稳定的状态存放在内容中,即使在服务器完全崩溃的情况下,WAL也能够保证数据不丢失,因为实际的日志存储在HDFS上。其他服务器可以打开日志然后回放这些修改。
Q: 除了 Undo Log 之外,是否还有其他方案可以实现 MVCC?
比如:使用版本号来标记每个记录,使用锁定机制来防止冲突,使用快照读取来实现读取的隔离性,使用多版本并发控制来实现写入的隔离性等。
Q: 基于代价的优化器一般需要考虑哪些代价?
总代价 = IO 代价 + CPU 代价COST = P*a_page_cpu_time + W * TQ: 执行器的执行模型,除了本课中提到的火山模型是否还有其他模型?相比于火山模型有什么优劣势?
物化模型(Materialization Model)——物化模型的处理方式是:每个 operator 一次处理所有的输入,处理完之后将所有结果一次性输出。物化模型更适合OLTP负载,这些查询每次只访问小规模的数据,只需要少量的函数调用。
向量化/批处理模型(Vectorized / Batch Model)——向量化模型 和 火山模型 类似,每个 operator 需要实现一个 next() 函数,但是每次调用 next() 函数会返回一批的元组(tuples),而不是一个元组,所以向量化模型也可称为批处理模型。向量化模型是火山模型和物化模型的折衷。向量化模型比较适合 OLAP 查询,因为其大大减少了每个 operator 的调用次数,也就简单减少了虚函数的调用。Presto、snowflake、SQLServer、Amazon Redshift等数据库支持这种处理模式。Spark 2.x 的 SQL 引擎开始也支持向量化执行模型。在 Hive 中使用 向量化执行的方式:1、必须以 ORC 格式来存储数据,2、将 hive.vectorized.execution.enabled 参数设置为 true
Q: InnoDB 的 B+ Tree 是怎么实现的?
基本特征:该数据结构的基本特点和性质: ①多路节点②一个树节点中,有多个数据,数据个数大于等于N时,分裂成三部分:左、中、右,这三部分变成三个树节点,中间树节点成为左右两部分的父节点。③所有叶子节点形成一条有序链表④所有数据都在叶子节点上
大体结构设计:①一个树节点看作一个类;②树节点类里面有多个数据元素节点,数据元素看作一个类;③树节点类中有父节点指针④数据元素节点中有左右子树节点指针。设计的是同一个树节点内,左边第一个元素节点左右可能都有树节点,其他元素节点只有右边有子树节点;⑤叶子节点中维护了一个前后叶子节点的指针,从而形成一条链表

结构设计:定义类①首先,B+Tree是有序的,存的数据类型是不确定的。所以需要一个比较器Comparable/Comparator,为了方便选择了Comparable。还需要一个泛型,但这个泛型具体的类型必须得实现了Comparable接口,即该泛型有上限,方便比较。②B+Tree,得持有一个整棵树的一个入口,即Root节点;一个链表的入口,即head节点。③B+Tree的结构特点,决定了它需要一些内部类。树节点内部类,树节点里面单个数据类。④BTree需要分裂平衡,触发条件是,当一个树节点的数据个数大于等于N时,向上分裂。所以需要一个全局变量N。
构造方法:要传递一个参数进来的,几路平衡树,即一个树节点有几个元素。关系到分裂平衡。
添加数据:①从root节点开始比较查找,依次比较根节点中所有数据元素。没找到合适的位置,继续往下一个节点找。②当定位到某个树节点,在该节点中找到插入位置,将数据插入树节点。③判断该树节点是否大于等于N。
a. 是,则将该树节点分裂成三个节点,形成一棵小子树。
b. 否,直接插入。
Q: InnoDB 的 buffer pool 是怎么实现页面管理和淘汰的?
A: innodb buffer pool 采用经典的 LRU 算法来进行页面淘汰,以提高缓存命中率。与传统的 LRU 算法相比,buffer pool 中的 LRU 列表其中间位置被打了一个 old 标识,可以简单的理解为将 LRU 列表分为两个部分,这个标记到 LRU 列表头部的数据页称为 young 数据页池,这个标志到 LRU 列表尾部的数据页称之为 old 数据页池。当一个页从磁盘上加载到缓存池的时候,会将它放在 old 标识之后的第一个位置,也就是说放在了 old 池子中(“中点插入策略”)。这个机制保证了在做大表的一次性全表扫描时,即使有大量新进来的数据页,也会被存放在 old 池子中,当 old 池子的大小不够缓存新进来页面的时候,也只是在 old 池子中进行循环冲洗,这样就不会冲洗 young 池子中的热点页,从而保护了热点页。这就是 buffer pool LRU 算法的简单机制。
Q: 列存和行存的差别是什么,使用场景有什么不同?
A: 分析类查询往往只查询一个表里面很少的几个字段,Column-Store只需要从磁盘读取用户查询的Column,而Row-Store读取每一条记录的时候你会把所有Column的数据读出来,在IO上Column-Store比Row-Store效率高很多,因此性能更好。当你的核心业务是 OLTP 时,一个行式数据库,再加上优化操作,可能是个最好的选择。
当你的核心业务是 OLAP 时,一个列式数据库,绝对是更好的选择。Q: 列存的优点有哪些?
A: 列存储数据库的优点有: 一、查找速度快;二、可扩展性;三、更容易进行分布式扩展
Q: 列存的缺点有哪些?
A: 整行读取时,可能需要多次I/O操作。
Q: 列存适合什么样的索引?
A: 列存储索引是聚集或非聚集索引。
Q: ClickHouse的列存是什么样的存储架构?
A: ClickHouse采用列存格式作为单机存储,并且采用了类LSM tree的结构来进行组织与合并。
Q: ClickHouse的索引是怎么设计的?
A: ClickHouse索引有主索引(Primary Indexes)和二级索引(Skipping Indexes)。一级索引:数据按照主键排序存储在磁盘上→数据被组织成颗粒以进行并行数据处理→主索引被用来选择颗粒→标记文件用来定位颗粒。
Q: ClickHouse的查询是怎么使用索引的?
A: ClickHouse使用它的稀疏主索引来快速(通过二分查找算法)选择可能包含匹配查询的行的颗粒。
