
更大的语言模型在In-context Learning上表现出的不同

本文首发于 机器翻译学堂
转载事宜请后台询问哦
译者 | 寇凯淇
单位 | 东北大学自然语言处理实验室


论文题目:Larger language models do in-context learning differently
论文机构:Google Research, Brain Team; Stanford University; Brown University
论文作者:Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, Tengyu Ma
论文链接:https://arxiv.org/abs/2303.03846
博客链接:https://ai.googleblog.com/2023/05/larger-language-models-do-in-context.html
引言
随着语言模型规模的越做越大,越来越多的大模型表现出来不俗的“语言理解能力”,前段时间,OpenAI研发的ChatGPT的面世更是给我们带来了很多关于大语言模型的讨论。其中,In-context Learning(上下文学习)被视为是一种随着模型规模增大而表现出来的能力。正是因为这种能力,大语言模型可以通过几个示例的输入来快速执行新的任务[1]。近期,Google Research通过论文和博客的形式发表了一项工作,该工作尝试通过实验来探究不同规模的语言模型所表现出In-context Learning能力中,模型的先验语义知识和模型学习输入-标签映射能力之间的相互关系。下面,让我们来一起看看Google Research这次带来了哪些发现吧!
何为In-context Learning
In-context learning是一种语言模型表现出的能力,也可以说是一种学习的范式。它最早是由OpenAI在GPT-3的论文[2]中提出并开始普及的,它通过在输入的文本中添加一个或多个任务示例,来使模型执行一个新的任务,并获得较好的效果。如下图的样例所示,我们希望让语言模型执行从英语到法语的翻译任务,所以我们在输入模型的prompt(提示)的最开始,通过自然语言对任务进行了描述“Translate English to French:”。而在prompt的最后,我们输入了我们想要翻译成法语的英文“cheese”。而在两者之间,我们又为prompt补充了3个从英语到法语的翻译示例,让模型更好的理解我们想要执行的任务。

这有点类似我们去解一道新的数学题的过程。面对一种新的题型,我们或许很难在第一时间做出解答,但如果给我们几道相同题型的例题与答案,我们就可以参考这些例题来学会解答这种题型。

需要知道的是,不同于Fine-tuning(微调)任务,In-context Learning不需要使用下游任务的数据集对语言模型的参数进行进一步的训练,而是在冻结模型参数的基础上执行推理任务。这使得用户无需耗费大量资源对语言模型进行训练,降低了模型对不同任务部署的难度。当然,在prompt中你所提供的示例也并不会被模型所学习记录,在处理相同任务的时候,你需要不断地为模型提供示例。
关于In-context Learning的原理究竟是什么,大家可以进一步阅读我们早些时候发表的《In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘》,它或许可以为各位解答一部分疑惑。
文章链接:https://school.niutrans.com/qualityArticleInfo?id=482。
模型的In-context Learning在做什么?
通常来说,语言模型能够通过In-context Learning来获取较为优秀的生成结果与以下两个方面有关(这里以针对电影评论的情感分析任务为例):
语言模型使用模型在预训练阶段学习到的先验的语义知识来对标签进行预测,同时模型会遵守上下文示例的格式。(即模型查看了带有“Positive”和“Negative”标签的上下文示例,并使用先验知识对句子进行情绪分析)
语言模型从输入所提供的上下文示例中学习到了一种输入与标签的映射,从而进行情绪分析。(例如,模型通过上下文示例找到了一种模式,正面的评论会被映射到一个标签上,而负面评论会被映射到另外一种标签上)
所以,文章设计了几个实验来探究这模型的先验语义知识和模型学习输入-标签映射的能力这两种因素在模型的In-context Learning的过程中所发挥的作用,特别是与模型参数的规模的关系。
实验设置

常规In-context Learning(Regular ICL):模型的输入示例是符合正确的语义且与标签匹配的,这样的情况下,模型的先验语义知识以及对输入-标签映射的学习能力都可以发挥作用,使得In-context Learning的表现更好。
翻转标签的In-context Learning(Flipped-Label ICL):将输入的示例的“Positive”与“Negative”标签翻转,原本积极的评论被标注为消极,消极的评论被标注为积极。这意味着输入模型的上下文示例的标签映射与模型所学习的先验语义知识不一致。因此,对与二元分类任务,如果在这个实验设置下,模型的表现优于50%的随机猜测的准确度,说明模型对输入的上下文示例的理解无法覆盖模型原本学习的先验语义知识。而表现低于50%准确度的模型则意味着该模型能够通过上下文示例学习输入-标签的映射关系,并且会覆盖原本模型学习的先验语义知识。
语义无关标签的In-context Learning(SUL-ICL):将输入模型的上下文示例的标签更换为语义无关的标签,比如将“Positive/Negative”更换为“Bar/Foo”。在这种实验设置下,标签的语义知识被移除,模型只能够通过对输入-标签映射的学习来执行In-context Learning。如果一个模型执行In-context Learning主要依赖于模型自身的先验语义知识,那么模型的性能应该会有所下降。从另一个角度来看,如果一个模型可以在上下文示例中学习输入-标签的映射,那么这种模型的性能应该不会出现严重的下降。
为了多样化的数据集组合,文章对七种广泛使用的自然语言处理任务进行了实验,分别是:情感分析、主客观分类、问题分类、重复问题识别、蕴含识别、金融情感分析和仇恨言论检测。并对五个语言模型系列进行实验,分别是:PaLM、Flan-PaLM、GPT-3、InstructGPT和Codex。

其中,GPT-3系列的模型的大小为babbage-1B,curie-6.7B和davinci-175B[2][3]。作者在文章中补充ada的模型大小为350M。InstructGPT[4]与Codex[5]系列模型是在GPT3模型的基础上微调而得的,其中code-cushman-001模型大小为12B[3][5],其余模型大小则无直接信息。根据对应的相关信息,其模型大小应该可以参考与其相同名称的GPT-3模型大小[3][4][5]。PaLM系列与Flan-PaLM系列模型大小被标注在表中。
翻转标签实验
就如先前介绍的实验设置那样,翻转标签实验设计是为了测试模型在In-context Learning的过程中能多大程度上学习上下文示例中的输入-标签映射并覆盖模型的先验语义知识。测试中,能够覆盖先验语义知识的模型的性能应该会下降到随机猜测的性能以下。
在这个测试实验中,设置了不同翻转程度的上下文示例来进行测试。比如,100%的翻转标签比例意味着所有标记为“Positive”的样本都会在上下文实例中被标记为“Negative”,而所有“Negative”的样本会被重新标记为“Positive”。
在评估的过程中并不会翻转测试样例的标签,即使用正确的标记对模型的输出结果进行测试。所以,对于一个可以完全覆盖先验语义知识的完美模型,对于100%的翻转标签比例,它的测试结果的准确度应该是0%。

观察实验结果,我们可以发现,随着翻转标签比例的增加,所有模型系列在都有着类似的变化趋势。当没有标签发生翻转时,较大的模型有着比较小模型更加好的性能,这是与预期相符合的。然而,随着越来越多的标签被翻转,特别是当全部标签被翻转之后,较小的模型性能变化趋势相对缓慢,并且其通常不会低于随机的猜测准确度(即50%)。而对于较大的语言模型,它的性能可以下降到远低于随机猜测的准确度,比如text-davinci-002的性能从原本90.3%的性能下降到了最终22.5%的性能。
这个实验结果表明,大型的语言模型是可以从上下文示例中学习输入-标签的映射的,并且新的知识可以覆盖原本在模型预训练过程中学习到的先验的语义知识。而小的语言模型则无法推翻先验的语义知识。这种现象表明,这种通过上下文示例学习输入-标签的映射的能力是只出现在大型的语言模型中,是一种通过扩大模型规模而涌现的新兴现象。
GPT-3模型在实验中的表现比较特殊,虽然性能降低到了50%,但很难进一步降低。即便在标签被100%翻转后,情况依旧,与小模型的表现相同。
语义无关标签实验
语义无关标签上下文学习(SUL-ICL)的实验将所有用自然语言书写的标签都用语义无关的标签替换。例如,对SST-2数据集(情感分析),SUL-ICL实验将标记为“Negative”的标签替换为“Foo”,并将标记为“Positive”的标签替换为“Bar”,然后对模型进行性能测试。结果如下图:

图中,浅色数据为执行SUL-ICL实验的性能,深色数据为执行常规ICL的性能。我们可以观测到,实验结果中与预期相同的是,随着模型规模的增大,模型在SUL-ICL实验上的性能与模型在常规ICL实验上的性能都有所提高。然而,对比同一系列不同规模的模型上两种实验是性能差距,我们可以发现,与大语言模型相比较,小的语言模型在进行语义无关标签实验时,性能下降的更大。这是因为,语义无关标签实验的设置使得模型输入的上下文示例的标签的语义被移除,小模型收到了严重的影响。所以小模型在进行In-context Learning的过程之中,更加依赖于标签的语义信息,而不是去学习示例中的映射关系。于此同时,大模型的性能下降却十分微小,这表明在标签的语义被移除后,大语言模型有能力从上下文示例中获取输入-标签映射。因此,在没有给出语义先验的情况下,这种对输入-标签的映射的学习能力也能被视作为模型规模增大而带来的新能力。
GPT系列中175B的davinci模型依旧展现出了与其他大模型性能不符的特点,与小模型的表现更为相似。
另外,在SUL-ICL实验设置中,随着上下文示例个数的增加,模型规模越大,其在实验中所表现的性能提升越多。这表明,大模型更有能力使用上下文示例中提供的额外的输入-标签映射来学习输入与标签之间的正确关系。测试结果如下图所示。

Instruction tuning为模型带来了什么?
作为对文章的拓展,文章还通过实验分析了Instruction tuning(指令微调)对先前提到的使用先验知识和学习输入-标签映射着两种能力的影响。Instruction tuning通过在微调阶段,用自然语言对任务进行描述并加入prompt中,来提高模型回答自然语言指令的能力[6]。同样通过先前设计的两种实验对普通预训练模型(PaLM)和指令微调模型(Flan-PaLM)进行对比。

在语义无关标签实验的结果中,指令微调模型的表现明显好于普通预训练模型,其中微调后的Flan-PaLM-8B模型性能追赶上了PaLM-62B。这说明指令调优增强了模型学习输入-标签映射的能力。
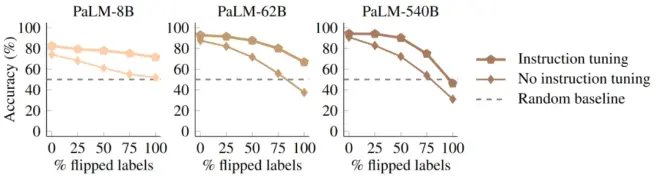
而在翻转标签实验中,指令微调模型的准确度要高于普通模型。这说明指令微调加强了语言模型对语义先验知识的使用,学习的上下文示例映射无法覆盖先验语义知识。可能是指令微调技术增加了模型对语义先验知识的依赖,或者提供了更多的语义先验知识。
尽管指令微调提高了模型学习输入-标签映射的能力,但它同时也加强了模型对语义先验的使用。
总结
这篇文章通过实验为我们展示了语言模型在上下文学习中的能力。当提供足够多的翻转标签时,大的模型能够学习新的映射并覆盖先验语义知识,这种能力随着模型规模增大而出现。同时,执行SUL-ICL设置的能力,即学习输入与语义无关标签映射的能力也是大模型的另一新能力。而指令微调技术同时提高了模型学习输入-标签映射的能力,也加强了语义先验对模型的影响。这些实验结果强调了语言模型的上下文学习能力是如何随着模型规模的增大而变化的,并且大语言模型展现出的新能力是一种真正的符号推理,可以学习任意符号的输入-标签映射。这种现象为什么会随着模型规模的增大而出现可能是未来的工作需要探讨的。
参考文献
[1] Min S, Lyu X, Holtzman A, et al. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?[J]. arXiv preprint arXiv:2202.12837, 2022.
[2] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[3] https://platform.openai.com/docs/model-index-for-researchers#footnote-1
[4] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[5] Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.
[6] Wei J, Bosma M, Zhao V Y, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.

hi,这里是小牛翻译~
想要看到更多我们的文章,可以关注下
机器翻译学堂(公号或网站)
笔芯~

往期精彩文章



