
[oeasy]python0020换行字符_feed_line_lf_反斜杠n_B语言_安徒生童话
换行字符
回忆上次内容
struct包可以让我们使用封包格式
遍历了一次ascii码
pack函数负责封包
unpack函数负责解封
把数字封包到字节里
我们通过封到不同的字节状态

还是有那片黑色的区域
好像是一片黑暗森林!
那里面到底有些什么秘密?🤔
我们这次向黑暗森林区域进发!!👊
整理行装
出发!
chr
先看看"oeasy"这个字符串是如何存在的🤔

字符都对应着一个数字
数字在计算机上究竟是如何存储的呢?
用二进制形式存储在字节中的
可以看看这个二进制形式么?
chr
8bit 构成 byte

上图的字节为
(0011 0101)2
(35)16
对应着字符'5'

那字母呢?🤔
abcd在内存里长什么样子?
文件编码
编写一个文件
写下 abcd
用
:%!xxd:%!xxd -r变回来

可以看到文件是用
2进制方式存储的0x61 - a
0x62 - b
0x63 - c
0x64 - d
不论是内存、硬盘还是网络传输
(0x61)16
(0b01100001)2
a 对应
图中最后的那个 0x0a 对应什么字符???
善用函数
使用chr得到相关字符

0x0a对应的是'\n'这个字符
这个字符好像在哪里见过?🤔
回到最初
想要了解这个'\n'
我们还得回到最初
我们回到开始的时候

前面介绍过
BWK写的 c 语言的第一个程序
\n
注意到
hello world后面的\n了么?这个方向
\叫反斜杠键盘位置在回车键附近
注意到
hello world后面的\n了么?特别注意斜杠的方向

那
\n到底是什么??🤔
输出"\n"
\n是一个整体占一个字节
算一个字符
序号是(
10)10进制也就是(
0x0a)16进制这就是在开篇时的
abcd后面的字符\n在内存里显示为一个.

我们直接把他输出看看
输出
输出
#输出\nprint("\n")#直接printprint()#查看序号ord("\n")#查看十六进制的序号hex(ord("\n"))
输出结果

好像换了
2行如果没
\n的话,只换1行如果有
\n的话, 就换2行我们看看ascii码表是如何定义的这第10个字符的
找到位置
我们已经身在在黑暗森林中
找到了一个落脚点

十进制的
10就是 十六进制的0x0A这个数值在
ascii码表中意思是LF啥意思?
搜索
搜索
\n得到的结果是这样的LF 意味着 Line Feed
喂行
喂一行纸
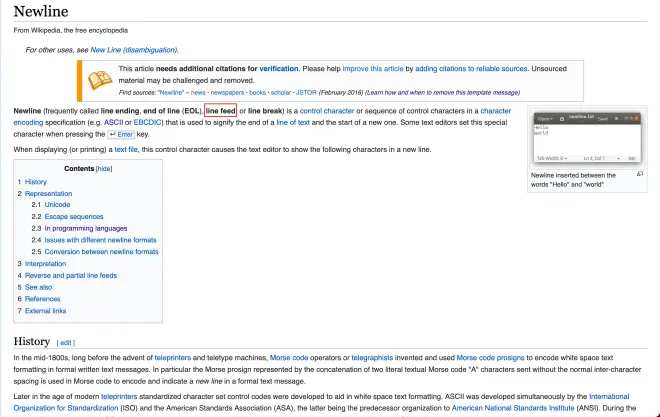
那我真的可以用这个
\n在字符中间换行嘛?
尝试换行
#输出字符串中带有\nprint("Hello\nWorld")
在游乐场中尝试

中途换行成功!
可以多来几个换行符吗?
多来几个
就往里面加
\n
#输出字符串中带有\nprint("He\nllo\nWor\nld")
显然这个
\n就是一个换行字符串里面有个
\n就意味着需要换 1 行他的英文是
Line Feed意思就是
新换1行这个东西其实比 ascii 的历史还要悠久
从打字机的时代就有了

为什么要有换行符呢?
换行符
最最开始的时候分段落
都是靠打字机输出空格完成换行
自从有了这个
LineFeed一个键就直接换行了
所以
LineFeed 极大地提高了效率

两个换行符就换两行
可以使用chr函数么?
使用序号得到换行符
#输出ascii值为10的字符chr(10)#把这个字符放在print里面输出print("hello"+chr(10)+"world")

纯文本中也会有回车符么?
我们去看看纯文本文件
打开文本文档
https://github.com/overmind1980/oeasy-python-tutorial.git
vi oeasy-python-tutorial/samples/000016/anderson_fairy_tales.txt
首先下载这个仓库
然后找到其中的安德森仙话这个本书

我们发现这个东西是318K
那他有多少字符呢?
字符数量
1个英文字符占一个字节
318k大概有318000个字节
大概是31.8万个字符

这就是文本文件的形式
第一行的Andersen后面有应该有两个换行符
是不是呢真有换行符呢?
字节形式
所有行转化为字节形式
%!xxd
查找0a
/0a

确实能够找到那两个换行符(0a)
这可以和纯文本方式对应起来吗?
纯文本方式
文本中的换行
其实就是换行符的效果
在文本观看模式下是换行

在字节观看模式下是0a
这本书后来被翻译成安徒生童话
安徒生童话
里面有很多耳熟能详的故事
《皇帝的新装》
《海的女儿》
《丑小鸭》
《红舞鞋》
《卖火柴的小女孩》
《拇指姑娘》

在安徒生所处的时代(1805-1875)
丹麦仍是一个君主专制主义社会
20年代经济衰退
童话用儿童视角透视复杂生活
万物有灵
风趣幽默
Jean Hersholt
将160个故事从丹麦文翻译成英文
刘半农 1914年
翻译了《皇帝的新衣》开始
叶君健 1944年到1949年
翻译了 安徒生童话全集
互联网时代
英文版安徒生童话被谷腾堡项目所收录
落实
文档当中就是用0和1来表示字符的
如下图所示
文字是蓝色的
字节是黑色的

为什么\n会用来表示换行(Line-Feed)呢?
追溯历史
c语言中的\n来自于什么呢?来自于
B语言B语言是里奇和汤普逊最早开发unix的语言B语言1969 年 就 运行在bell实验室的PDP-8上1971 年里奇和汤普逊开始对于
B语言进行改造改名叫
c语言在新买的
PDP-11上用B语言给B语言写扩展,称之为NewB1973 年
NewB基本主体完成所以
c其实是NewB他们用手头的编译器和
c语言给PDP-11重写了一个Unix Kernel机器语言和汇编语言本来不具有移植性
就像x86的二进制程序不能直接运行在arm上
需要移植
c语言程序却可以在很多架构的处理器上编译运行也就是今天所说的交叉编译
只要那种架构的处理器具有对应的
c语言编译器和库那就能顺利编译成针对该处理器架构的二进制程序
甚至能实现跨平台编译
这就是
c语言在当时能够发展的原因

c语言源自B语言B语言也不是凭空创造的源自什么呢?
Basic Combined Programming Language(BCPL)
B语言源自BCPL(Basic Combined Programming Language)1967 年由剑桥大学的
Matin Richards制作

在同样由剑桥大学开发的
CPL语言上改进而来BCPL最早被用做牛津大学的OS6操作系统上面的开发工具
后来通过美国贝尔实验室的改进和推广成为了
UNIX上的常用开发语言最早
BCPL语言的样子就有个类似于l(ine)f(eed)的符号这是关于换行符表示法 最早的记录
当时的换行符长什么样呢?
BCPL的换行符
当时的换行符长成这样
!*n

上述程序的目是
输出 hello,world
然后再来个回车
所以hello world
并不是c语言的发明
而是从c语言的爷爷bcpl那时候就有了
并且从bcpl时代就已经作为迷因(meme)开始传播
python虚拟机的可执行文件
也就是pyc文件是如何理解换行符的呢?
反汇编(disassemble)
观察一下

\n出现在字符串常量中
能在pyc中找到这个常量么?
先编译
将py文件编译成pyc文件
再观察
pyc文件
打开pyc文件
确实能够找到a和s之间的\n
也就是(0a)16进制
任务完成!!!
总结
\n就是换行符号换行符对应着
ascii字符的代码是(10)10进制换行符的英文是 LF
意思是
Line Feed我们可以在《安徒生童话》的文本中
找到每个字符对应的字节形态
不光txt文件是文件
我们的python游乐场本质上也是一个二进制可执行的文件
这个文件在哪?
我们可以读懂这个可执行文件吗?🤔
我们下次再说!👋
蓝桥->https://www.lanqiao.cn/teacher/3584
github->https://github.com/overmind1980/oeasy-python-tutorial
gitee->https://gitee.com/overmind1980/oeasypython
视频->https://www.bilibili.com/video/BV1CU4y1Z7gQ 作者:oeasy
