
NovelAI-embeddings模型训练(教程)

这段时间问我怎么训练模型的私信很多, 我这个教程与其说是教程, 更应该说是我自己训练方法的一次记录, 做模型教程的up主很多, 如果我的方法你觉得不合适, 那你可以尝试其他up主的,毕竟这种东西没有最好的, 只有最合适的.
我写这个教程是想把一部分参数的意义说明白, 但是我不是ai方面的专业人士, 如有错误, 欢迎指正, 非常感谢.
首先你想开始训练, 建议你拥有一张8G显存或以上的显卡, 没有的话可以参考其他人发布的飞桨平台云训练.

基础知识:
首先, 先来说一下基础概念: 机器学习学习率, 损失函数, 过拟合
(我本职不是ai相关的, 我是本职是数据分析师, 这里的只是我在闲暇时间自学的,如有错误,欢迎指正, 感谢感谢.)
损失函数(loss function):
是用来估量模型的预测值f(x)与真实值Y的不一致程度, 它是一个非负实值函数, 通常使用L(Y, f(x))来表示, 损失函数越小, 模型的鲁棒性就越好. 也可以简单理解为与学习的目标图像更加接近. 在实际使用中, 损失函数越低, 画面效果一般较好, 但是由于不同素材本来就存在差异, 所以损失函数最后会稳定在0.13-0.08之间, 如果你的损失函数长期稳定在0.25-0.17之间, 你需要检查你的原始素材是否存在较大差异, 比如不一致的服装, 极大的画风差异等.
如果你的损失函数长时间在0.3以上, 那我的建议是寻找前面损失值较低的存档重新开始训练, 可能是炸炉了.

Embedding模型学习率(Embedding Learning rate):
学习率LR表征了参数每次更新的幅度, 学习率过大, 前期收敛速度很快, 但是很快就会停止收敛, 因为学习率步长已经大于模型最佳点与目前位置的距离. 学习率过小, 会出现收敛速度慢导致数据更新时间极长. 但是在完成模型学习后, 会得到更精细的模型.为了方便读者更好的理解,我画下了一个草图(真的是随手画的, 我自己也知道很丑).


过拟合(Overfitting):
在制作模型的时候, 我们追求的肯定是损失函数的压缩, 但是压缩到一定程度就会出现一个问题, 一个模型专精程度越高, 泛化性越低.
比如你想训练一个tag, 叫做树叶(leaf)
你在处理训练集的时候,放入了以下图片:



你开始训练完以后, 会出现一个情况, 就是你画出来的所有树叶, 都是带锯齿边缘的, 因为在训练集中存在锯齿边缘的树叶, ai会认为树叶都带锯齿,开始钻牛角尖, 无论画什么树叶都会有锯齿.
解决办法是人工细化tag, 比如分别建立三个tag:maple leaves(枫叶), Banyan leaves(榕树叶),Mint leaf(薄荷叶), 这样就能在一定程度上压缩过拟合问题的发生.
实操
基础知识讲完了, 下面开始说具体步骤, 以webui为例.
第一步: 卸载models包离得vae文件
一般是直接找到vae文件, 在其前面加个1让他无法被读取.

第二步: 寻找训练所需素材, 我一般是在pixiv收集素材的, 收集素材需要注意以下几点:
1. 数量不用太多30-50张为佳, 质量比数量更重要
2. 要找清晰地, 单人的图片, 没有复杂背景效果最佳
3. 服装必须相同, 否则服装细节会模糊甚至错误
第三步:
创建空白Embedding
1. name栏填入你喜欢的名字
2. 选择合适的向量token数
什么是向量token数?
Number of vectors per token(每个向量所拥有的特征数), 可以简单得理解为特征数更多, 所获得的的模型细节越多
(1)不同的向量token数有什么区别?
1-2: 只有简单且模糊的人物轮廓, 无法使用单tag正常成像,
3-5: 有较清晰的人物图像, 但单tag生成效果不好
6以上: 基本能实现单tag成像
(2)6以上有什么差距?
可以参考之前我之前发布的的专栏最早期的两个模型是6-15token的, 然后token数每次都有一定提升, 每个模型大概提高5个点, 目前最先发布的阿罗娜我没记错的话是55-60这个区间的
(3)向量token数是不是越大越好?
在6-25这个区间内越大越好, 但是在55以上之后就没有太大的区别了(建议不要超过60), 较高的向量token会导致训练所需的迭代次数提升, 降低训练效率, 自己做取舍.

第四步:
图像预处理
这一步很多up主建议自己剪, 但是我比较懒, 而且我觉得人工剪的意义不是很大, 我一般直接使用webui它自带的预处理功能.
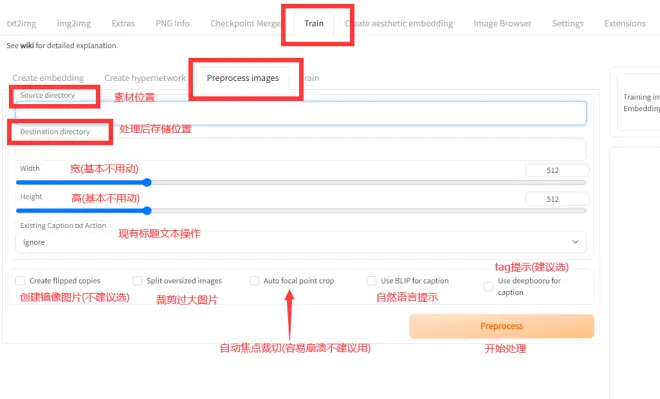

处理完之后会获得如下图像与文本

一个图对应一个提取tag的txt文件
先看一下自动预处理出来的图像, 有没有什么部分缺失, 或者有没有什么东西需要额外强调, 这时候就可以人工一1:1的比例切个512*512的图片添加进去, 然后就可以开始训练了.
第五步:
开始训练

这里就要提到学习率问题:
开始的时候, 选择默认的0.005学习率开始训练, 大概在一万两千步左右( 具体情况看实际渲染图, 最多的时候可能要到两万多步才清晰 )时, 训练过程渲染图会变得清晰, 且最近的几个渲染图都会很接近.
这时候可以进行第一次学习率压缩, 点击停止训练, 然后调节Embedding Learning rate的数值, 我一般第二个学习率数值为0.0001, 然后重复上面的操作, 等待图像清晰.
图像再次清晰, 可以再次进行学习率压缩, 我的习惯是直接在小数点后面加个0, 比如第二次是0.0001, 那第三次就是0.00001
但是, 学习率最小值不建议0.000001( 不用数了, 小数点后5个0 ),因为训练图像分辨率被压缩为512*512, 部分精细的细节在预处理时已经丢失了, 再降低学习率也没有意义, 图像细节不会有任何变化.
其他问题
(1)如果有些模型有些特殊细节, 比如眼睛是星型瞳孔, 要怎么训练?
多训练一个针对性模型, 选择画风模板来操作, 只投入所需的眼睛图片试试.
(2)为什么ai画的眼睛会糊?
因为机器学习的目标就是降低损失函数值, 而损失函数值是根据特征判定的, 所以在迭代时, 模型会逐渐记录起大量高频特征. 但是不同画师画出来的眼睛是不同的, 即使同一个画师在不同的画里也会有差异, 所以模型会把大量特征拼凑起来, 组建出一个损失值更低的模型, 导致眼睛放大看会糊.
(3)如果我想要的角色是异色瞳, 但是瞳色左右颠倒了怎么办?
不要使用图像预处理的镜像图片功能, 就能减少异色瞳瞳色反转的发生率, 生成的图片瞳色反转了, 可以尝试用这张图片生成镜像图片.
(4)为什么生成出来的图片这么糊, 有没有办法提高画质?
第一, 你可以提高迭代步数, 一般拉到50-70之间就足够了(我预渲染一般选择50步);
第二, 你可以打开Highres. fix功能, 能提高图像清晰度.

第三, 你可以训练与你使用的Embedding配套的hypernetwork模型来补充细节.
第四, 使用超分辨率重建软件, 我用的是在github上下来的realesrgan-gui
链接为:https://github.com/TransparentLC/realesrgan-gui/
如果你上不了github也可以在我之前发布模型的那个百度云文件夹那里下载,链接为:
链接:https://pan.baidu.com/s/1MX0uRxxI5L2FTbQhhqYyiQ?pwd=0lx4
提取码:0lx4
我使用的设定如下:


后记
ok, 差不多就这些, 有问题可以私信或者评论, 有空的时候会回复, 前提是不要太多, 太多把我干懵了可能就直接不看了.
