
CLIP 改进工作串讲(下)【论文精读·42】

CLIPasso
(CLIPasso: Semantically-Aware Object Skectching)
将CLIP做teach, 用它蒸馏自己的模型

- semantic loss: <原始,生成>特征尽可能的接近
- 几何形状上的限制,geomatric loss: perceptual loss把模型前面几层的输出特征算<原始,生成i>的相似性,而不是最后的2048维的特征(因为前面的特征含有长宽的概念,对几何位置更加的敏感)。保证几何形状,物体朝向 位置的一致性
- 基于saliency的初始化方式:用一个训练好的VIT,把最后一层的多头自注意力加权平均得到一个saliency map,对saliency map显著的地方进行采点。(在显著的地方采点其实就相当于自己已经知道了这个地方有物体或已经沿着这个物体的边界画贝兹曲线了)效果更稳定

- 一张V100 6min 2000 iters
- 后处理:一张input,三张简笔画,取两个loss最低的那张
优点:
- zero-shot: 不受限于数据集里含有的类型
- 能达到任意程度的抽象,只需要控制笔画数

局限性:
- 有背景的时候,效果不好(自注意力图等不好)-> automatic mask的方式如U2Net,将物体扣出里(但是是two step了,不是end to end)
- 简笔画都是同时生成的,不像人画的时候具有序列性(做成auto-regressive,根据前一个笔画去定位下一笔在哪)
- 必须提前制定笔画数,手动+同等抽象度不同图像需要的笔画数不一样多,(将笔画数也进行优化)
CLIP+视频
CLIP4clip: An empirical study of CLIP for end to end video clip retrieval

视频是有时序的。一系列的帧,10个image token(cls token)如何做相似度计算:
1.parametr-free 直接取平均(目前最广泛接受的)。没有考虑时序,区分不了做下和站起来
2.加入时序,LSTM或transformer+位置编码
late fusion:已经抽取好图像和文本的特征了,只是在最后看怎么融合

3.early fusion:最开始就融合
文本和位置编码, patch喂入一个transformer

直接拿CLIP做视频文本的retrieval,效果直接秒杀之前的那些方法
少量数据集:直接mean效果最好(CLIP在4million上训练的,微调反而不好)


So, 大家都是直接mean
insights:

Gradient search,多试几组学习率。
ActionCLIP: 动作识别
动机:
- 动作识别中标签的定义,标记是非常困难的。
- 遇到新类,更细粒度的类

因为这里的文本就是标好的labels,非对角线点也可能是正样本。->交叉熵换成KL散度(两个分布的相似度)
三阶段:pre-train, prompt, finetune

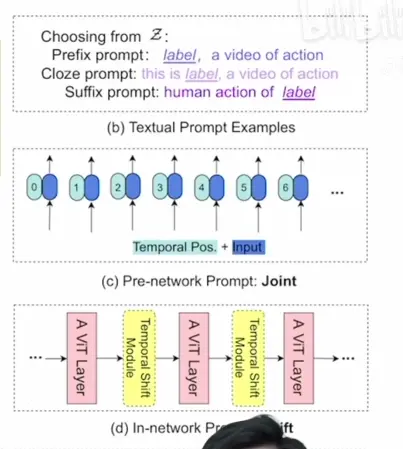
shift: 在特征图上做各种各样的移动,达到更强的建模能力。没有增加额外的参数和存储。
19年tsm将shift用到了时序
shift window,swin transformer里有用到

multimodal framework: 把one hot的标签变成language guided的目标函数
都是RGB+分类,使用CLIP预训练好的效果更好

因为识别的数据集很大,funetune足够了

zero/Few-shot的能力:

视频还有很多难点
拿CLIP作为visual encoder for diverse 下游vision-language tasks的初始化参数, 再finetune
AudioCLIP

文本,视频(帧),语音成triplet
三个相似度矩阵,loss
zero-shot语音分类
数据集很小
只要是RGB图像,CLIP都能处理的很好

prompt: 明确告诉是点云
把深度估计看成了一个分类问题而不是回归

类别和[0.5,1,1.5..]对应
总结:
1.仅用CLIP提取更好的特征,点乘
2.clip做teacher,蒸馏
3.不用预训练的CLIP,仅用多模态对比学习的思想
