
运维实战:Ambari开发手册-DolphinScheduler集成实操
继我们被apache linkis社区翻牌子以后,收录了几篇文章,今天被小海豚社区官方翻牌子了哈,当然我们也有flink社区的大佬,贡献flink社区文章若干,那就今天继续更新一篇小海豚的文章哈,本文章来自涤生大数据老师,阿里巴巴技术大佬贡献
Ambari集成大数据组件系列
1.背景
DolphinScheduler本来提供了Ambari的安装程序,可以直接集成的。但是呢,Amabri停止维护了,DS对应的安装代码也就没再更新了。DS最新版本已经到3.x了,但是安装部署脚本依旧停留在DS 1.3.8,这太Low了,一点都不适用。对此,咱们就来改改,来实现DS 3.x 在Ambari下的集成实现。
2.RPM制作
安装的方式有很多,但是个人还是比较喜欢AMbari的安装风格rpm,对此,依旧沿用此方法,先把我们的安装包封装成RPM。
2.1 软件包准备
官网下载对应的软件包信息,切记!!不要选最新版本的,选次新版本。别问,问就是血的教训。
截止2023年4月,最新版本为3.1.5,咨询了社区那些,相对比较稳定的版本是3.1.2,对此,我们选择3.1.2来进行实际环境的安装。此处,我们需要进行rpmrebuild的环境的制作,可参考百度rpmbuild的使用。然后,将我们的DS软件,解压并拷贝到对应的编译目录,待用。特殊说明:1.安装目录软件后续的安装目录,沿用HDP的路径:/usr/hdp/3.3.1.0-001/dolphinscheduler;2.编译目录rpmbulid打包成rpm时候用到的目录,主目录在
/root/rpmbuild/BUILDROOT/;
3.软件包目录
apache-dolphinscheduler-3.1.2-1.x86_64;4.软件包内的安装目录/usr/hdp/3.3.1.0-001/dolphinscheduler;所以,整体的DS的解压完整的路径是:
2.2 SPEC文件编辑
SPEC文件,是RPM制作的说明文件,我们可以完全自己写,也可以抄一个现有的。对于看这个文档的小伙伴,直接抄我的即可。完整的内容如下:
里面的具体内容与细节,参考《RPM SEPC文件解读》,此处不在复述,能用就行了,要啥自行车。说明下,这个rpm的SPEC内容,是用DS官网的1.3.8版本RPM包改的。
2.3 rpm制作
有了rpm包信息,有了SPEC说明文件,剩下的就简单了,直接使用rpmbulid -bb 进行编辑即可。
剩下的交给时间即可。
我们的rpm信息就制作完成了,在HDP的repo目录,创建一个dolphinscheduler 的目录,拷贝进去
最后用yum验证下,是否能够正确识别到。
2.4 长久之计
问题来了,如果下次DS升级版本,或者添加什么内容的。那么就需要重新制作RPM,以上操作再来一次。很明显,这种B格一看就不是大佬的作风。要玩,就长久点,代码能搞的,咱们就不动手。(有同样功能的,参考bigtop)我们的目的,是在DS有更新后,能够自动创建更新,创建rpm信息。自动检测一看就比较难,而且价值不大,咱们就不做了。我们把2.1 - 2.3 的步骤全部自动化,还是有十分可观的价值的。
首先,需要解决如下几个问题:
· 编译目录:/root/rpmbulid/BULIDROOT/.. ,这个目录下的文件回自动删除,我们每次构建都需要创建一次。
· 多版本支持,能不能每次自动更新release信息,自动保存历史记录。
带着疑惑,咋们就开始出发。
· 首先第一点,解决缓存文件被删除,无长久保存的问题。关于这个问题,从两方面进行考虑:1. 创建一个长久地址,每次封装的时候,拷贝次文件夹的内容来生成临时目录;2. 修改spec内容中的file部分,不写详细的文件列表,只写目录即可(2.2 已经修改)。
· 再然后就是release的更新了。这个就简单了,分为现有版本的获取与SPEC的更新。获取可以通过扫描repo中的文件列表,提取固定字段来获取。比如:apache-dolphinscheduler-3.1.2-3.x86_64.rpm中的3就是Relase的版本,查询 + 排序即可搞定。Relase的替换,也简单,拿到这个数字后,加1后,使用sed命令来进行替换即可。
最后,再来自己加点难度。比如,最好适用hdp的其他程序,和变量相关的,丢前面。尽量使用函数进行封装等。
接下来,上完整代码

代码解读:第一段:各种变量的定义,如果其他程序,改路径和版本即可。比如ambari的打包,修改配置如下
第二段:获取版本信息。获取现在的最新版本信息;函数:spec_config。此函数,先拷贝一个模板spec文件,步骤2.2 做好的东西,然后使用sed进行版本的替换
函数:buildroot_initx0; 这个是为了方便创建永久保存的目录:${src_path}。就第一次运行的时候运行;函数:buildroot_createx0;,进行rpm的封装。从${src_path}路径拷贝最新的文件到缓存目录,然后运行rpmbuild -bb 进行实际rpm的制作;整体函数使用for循环,进行文件列表循环,以适应多个包的更新;最后的最后:更新rpm信息:createrepo ./演示示例:
有了此代码后,更新就简单多了。比如我们想修改DS的存储为Mysql,需要添加mysql-connection-java.jar 到DS 各个程序的lib中。首先第一步,下载jar包:mysql-connector-java-8.0.26.jar第二步:拷贝此jar包到alert-server/libs,api-server/libs,master-server/libs,worker-server/libs第三步:运行程序。就会自动封装:apache-dolphinscheduler-3.1.2-4.x86_64.rpm
3.Dolphin集成
为了调试DS的安装,本人按照官网的安装教程,使用自带的安装程序install.sh N次后得出的结论。有兴趣的小伙伴,可以自己折腾下。
3.1 DS服务架构
盗的一个架构图,一看就比较复杂。
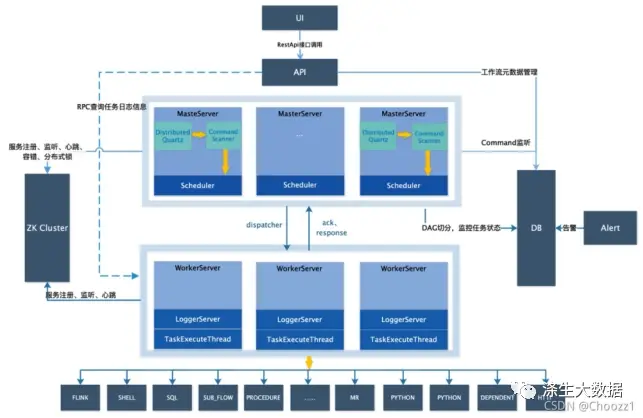
不过从图中可以看出,有ZK,有API、UI、DB、Alert、Master、Worker。这些,其实就是我们安装部署过程中需要运行的程序。安装DS前,需要有ZK集群以及一个Mysql。UI页面是封装到API中的,后面的Alert,Master,Worker每个作为单独的程序来运行。那么对于我们自动化部署,就是要实现DS的四个程序的启动。
3.2 代码结构
有了架构图,大概对这个软件有了大概的意思,但是这东西来得不实际,很飘。涉及到具体部署的时候,拿来没啥用。最有用的,还是看安装的压缩包。第一层目录,直接拆分了角色了,一下就清爽多了,一看就懂了,每个角色程序,一个文件夹。
随便进一个角色的目录:api-server
和这个角色相关的东西,大体有以下目录:
除了服务以外,还有一个特殊的目录 bin/env ,这个下面有两个文件,在安装的时候需要进行配置的修改,用于安装,初始化的时候需要,也要做对应的修改。
3.3 安装实现
目录结构看完了,部署大体结构也知道了,接下来就要开始进行实际的自动化实现了。
3.3.1 服务定义:metainfo.xml
这个是定义服务的程序,定义软件版本,安装的包信息,以及配置依赖信息。此处只贴了些案例,没贴全。模块一:服务定义
这个的效果图,在服务添加页面展示:

模块二:程序定义。主要定义包含哪些程序,以及程序的维护程序,定义等等各种东西,一共有四个:DOLPHIN_MASTER,DOLPHIN_WORKERx0;,DOLPHIN_APIx0;,DOLPHIN_ALERTx0;。单个参考如下,具体细节百度知。
模块三:安装rpm定义这边定义需要安装的rpm程序,以及系统。我们这里能支持的是Centos7.x/8.x, Redha7.x/8.x, Kylin V10,Anolis 8.x ,直接写个any先用着吧。
剩下的,还有点内容,后期加吧,这里贴一个完成的图。
3.3.2 程序安装:master_install.py
上面服务定义好了,接下来就进行软件的安装流程。就是看服务定义中的“scripts/dolphin_master_service.pyx0;”程序内容。这个里面呢,就是定义各个软件的安装与启动程序。以下,是经过N多次改版过后的实际安装代码。
具体内容,其中,服务安装的程序在下面代码的:install_packages中,会根据3.1.1中,os处定义的内容,来进行rpm包的安装,此处实际执行命令:yum install -y apache-dolphinscheduler*
其他安装程序,类似,只是需要修改对应的路径和文件名信息
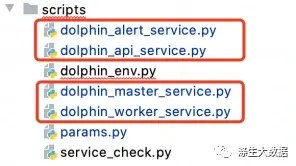
特殊说明下,最开始的程序,需要做系统的初始化,沿用1.3.8版本的初始化逻辑,把数据库的初始化放在api的启动程序中:dolphin_api_service.pyx0;
3.4 配置管理
你以为上面写好就能用了?肤浅了,格局一定要打开。安装才是第一步,怎么做配置的更新、管理才是一个好的部署平台。最好自动化安装,点一下需要安装的程序,剩下的全部根据集群,系统来默认最优配置设置,这才是一个大佬应该写出来的自动化程序。其实,3.3中的程序,已经包含了配置的更新,其中,每个控制模块前的import params 和set-params 即配置的读取与更新程序。
以上代码,对应的程序
3.4.1 配置解读
在我N多次的安装、卸载,对比配置等各个操作手段后,得出了以下内容。需要修改的配置内容如下,以ds的安装相对路径进行文件的书写。
差不多,这些配置都得改吧。
3.4.2 confiuration配置管理
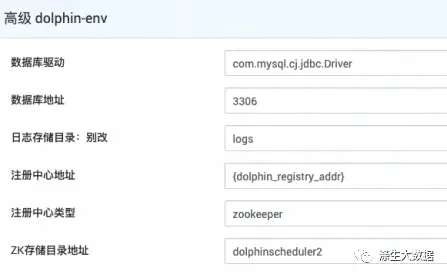
对于配置相关的管理,在Amabri中,是通过一个叫configuration相关的xml进行设置的。这里以dolphin-env.xml比如配置./bin/env/dolphinscheduler_env.sh中的一个配置
其中在configuration中的相关定义如下:
特殊说明,这种类型不太一样,数据库类型提供的是一个多选,提供mysql个PG的单选按钮,数据库是一个字符串,不用高级设置。成品大概如下:


特殊说明下,我是代码搞好后再写的文档,截图和xml中的定义,不太一样。
3.4.2 params配已置读取
接下来,数据的定义有了,那就需要进行数据的读取了,在web页面,如果修改了配置,需要将这个配置写入到具体的配置文件中。怎么来读取这个配置呢?这个写入在脚本parms.py中,先来一个案例:
案例解读,这里就是定义各种变量信息的。比如读取“dolphin-envx0;.xml”中关于mysql类型的定义为:
玩得再花一点,就再写点判断,这样就可以根据一个选择来进行不同数据的定义。除了这种定义的以外,还有和集群相关的配置,比如ZK相关的,可以根据ZK集群的信息,自动读取ZK配置,具体写法如下:
剩下的,自己更具配置的内容添加即可。
3.4.3 Templates模板生成
数据配置定义了,数据配置的方法读取方法获取了,接下来,问题来了:怎么把这些信息写入到具体配置里面呢?这里,使用Templates模板来进行配置文档的编辑。此处核心就是配置使用 {{变量名}} 来进行替换首先用application.yaml来打个样。
其中:{{application_jdbc_type}} 等,都是parms.py中进行的变量获取。整体套路就是这样,剩下的就是对比不同的配置,来制作多个模板。全部的信息如下:
这里只是完成了一半,另外的一半,需要定义这些模板文件,需要写到哪些配置里面。这里的话,写在了dolphin_env.py 中,这里面主要进行文件夹的创建,以及配置的更新。
以上为案例,一看就懂,不做解释。剩下的就是体力劳动。到此,已经可用了,写到这里,自动化部署就已经完成了。但是,还是那句话,格局一定要打开,要最求卓越。

3.5 themes视觉优化
以下两个图,那个好看?很明显,不做选择题,咋们全都要。只是,上图已经实现了,接下来进行下图的实现。
其中,下图的内容需要使用到的是Ambari提供的Themes 模板,类似于一个页面编辑框的工具,可以将单单选,多选文本的换个花样来展示。
3.5.1 themes解读
首先来看看themes的写法,大概长这样的,主题包含三个目录。layouts,placement和widgets
layouts:是对整体页面做拆分,做页面排布。并对每个页面命名和编号。页面的布局内容如下:

placement,是对定义在框框中,填入什么样的内容。比如JVM处,大题填以下内容:

widgets,则是定义数据的规范,和显示的格式,这个需要和对应的xml中的配置遥相呼应。比如:text-fieldx0; 文本框,就是单纯的框框格式,比如环境配置信息的

togglex0; 二选一的拖拽框,比如,是否开启kerbers配置的选项


combox0;,下拉框,用于多选一的选择,比如数据库类型,文件存储类型等。
大体介绍完了, 接下来进行实际的实现。
3.5.2 目录配置
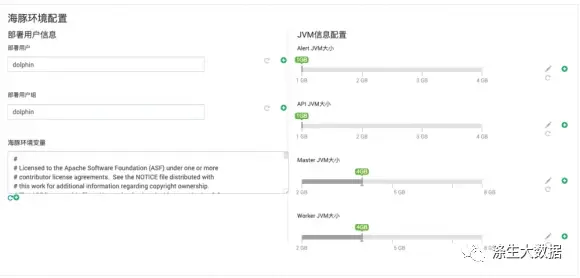
我们在最开始的地方<0,0>来进行环境配置的设置。打算提供,用户账号、组,以及环境变量的定义。这里采用的是大框套小框来进行实现的,整体页面布局就,及其对应的编码就变成了这样。

接下来就进行具体的框框的定义。在configurationx0;.layoutsx0;.tabs.x0;sectionsx0;处进行定义,从外部定义到内部,逐级定义。
接下来,定义这个框里面需要输入的数据:账号、组,以及环境变量;在配置位置:configurationx0;.placementx0;x0;.configsx0;
最后,定义处这些内容的数据展示格式。在配置configuration.widgetsx0; 处
这里都是text格式,对应的一个xml案例,dolphin-env.xml 关于部署用户dolphin.user的定义。
通过以上,操作,最后的效果图如下。

3.5.2 JVM配置
同上,依旧来进行JVM的设置,复制 3.5.1开头的内容,先来进行JVM的位置信息设置。他的位置是<0,1>;
接下来进行对应数据的填充与设置,同上,这里只提供一些参数的设置,其他的,参考排布即可。
与上图不同的是,这里采用拉条的方式来进行数据的数据的设置,左右横拉,实现JVM的设置。其中,在themes中的数据定义如下:
对应的xml信息,在配置dolphin-jvm.xml中,每次可调节1G大小,允许设置的范围为1-4G,可以根据具体的配置设置。
最后效果案例效果。

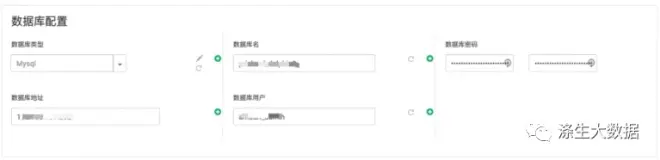
3.5.3 数据库配置
数据库的,同上。不整废话,都一样的东西。效果图如下:
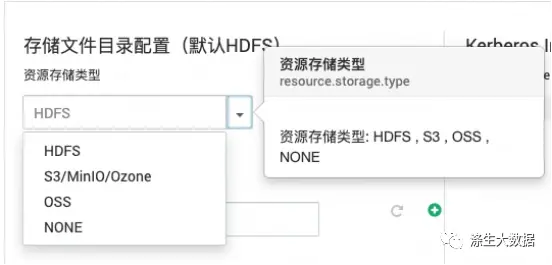
3.5.4 存储类型选择
数据存储类型的时候,这个有点不同了,因为添加了可选,并且可选进行数据内容的展示。先来看效果图:
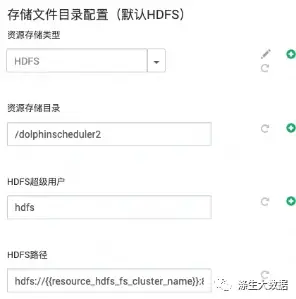
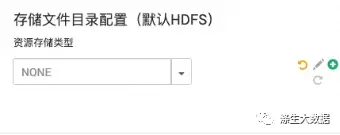
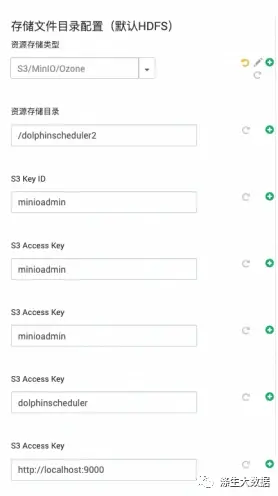
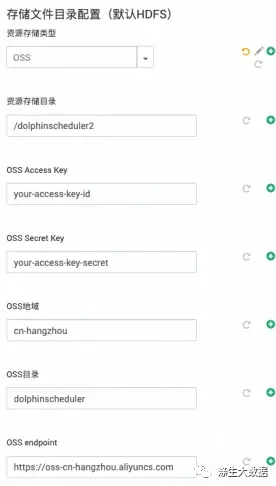
选择HDFS为存储后,对应的配置如图左上;选择Null的效果如右上;Aws S3及其同类产品的如左下;阿里云OSS的如右下。这个是怎么实现的呢?关于图表框的定义,同上。不在叙述。接下来就是关于具体内容的选择,这里设置不一样了。首选,下拉框,选择存储格式,下面定义数据的输入
对应的数据格式为:
对应的xml定义文件:common.properties.xml,这是一个多选
这样,下拉框就完成了。接下来,怎么根据下拉框的格式来进行相应配置的选择呢?其实,这个的重点就是判断 + 可显示字段的信息标记。贴代码就懂了。在数据展示处:
在每个选项中,添加一个判断,只有当type类型相关的时候,显示标记位再设置是否显示。这样就完事儿了。
3.5.5 Kerberos & Wechat
这两个功能还没设置好,先把功能页面开启来先。
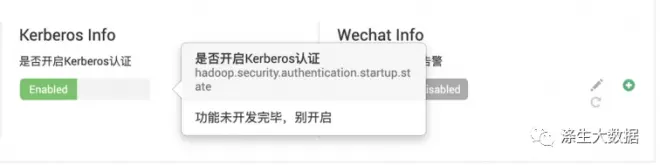
数据框,及其框中数据编辑都同上,不在叙述。不同就是数据的定义:
对应的XML数据定义,剩下的自己复制改。
通过以上一波操作,就全部完成了themes的定义,重点配置丢这里,看起来就舒服了。这样,重点配置在Setting页面,详细配置在advance页面。
3.6 超链接实现
DS给提供了Web页面,最好的话,再搞个超链接,点击即可访问。说干就看,先看效果图
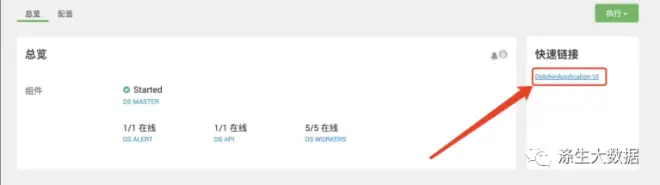
这个功能一共需求两个东东。
第一个,服务定义metainfo.xml中,需要添加关于超链接的定义。
在新建文件夹quicklinks,并在下面新建文件quicklinks.json案例数据如下,具体内容,自己百度。
这个改起来简单,效率给力。到此,文档完毕,还有监控和告警相关的,不想写了,就是这么有脾气。不是代码不想写,而且不想写文档。因为干IT最讨厌两件事:自己写代码的时候,写备注+文档、看别人代码的时候,没备注和文档;

欢迎在研究大数据集群二开的朋友们来战(交流交流哈哈哈),也可以在b站上看我录制的apache hadoop集群运维实战哈

本文使用 文章同步助手 同步
