
涤生大数据平台实践:如何高效备份Hive表结构?
在当今数据驱动的大数据时代下,数据的完整性和可恢复性对于任何企业都是至关重要的。Hive作为一种流行的大数据处理平台,广泛应用于数据仓库和分析场景中。在这种环境下,备份Hive表结构是保证数据完整性和可恢复性的关键步骤之一。
Hive表结构包括表的列名、数据类型、分区等重要信息,它们定义了数据的结构和组织方式。当出现数据丢失、表结构变更或其他问题时,备份的表结构可以帮助我们还原表的定义,避免数据丢失和结构变更带来的问题。
因此,高效备份Hive表结构对于保护数据资产、减少风险以及提高业务连续性至关重要。
常规的备份方式有以下几种:
方式一:利用元数据存储库备份
Hive的元数据存储库是保存表结构和元信息的关键组件,备份元数据存储库可以直接还原表的结构信息,避免重新执行DESCRIBE命令的开销。定期备份元数据存储库是备份Hive表结构的一种高效方式。
1.确定元数据存储库类型:Hive的元数据可以存储在不同的数据库中,如MySQL、Derby等。常用的一般是mysql。
2.定期备份元数据存储库:设置定期备份元数据存储库的计划,确保备份的频率适合您的业务需求。使用数据库备份工具或手动备份元数据存储库,并确保备份文件的安全存储。
3.测试还原能力:定期测试备份的还原能力,包括还原元数据存储库和验证表结构的一致性。这可以确保备份的有效性,在需要时快速恢复表的定义。
下面是一个基于mysql做数据备份的定时脚本示例:
方式二:自动化备份脚本
编写自动化备份脚本可以简化备份过程并确保备份的及时性和一致性。
1.创建备份脚本:编写脚本来执行DESCRIBE命令,并将其输出保存到文件中。脚本可以使用Hive的命令行接口或其他编程语言(如Python)来执行。
2.定时执行备份脚本:设置定时任务,以便定期执行备份脚本。根据您的需求,选择合适的备份频率(如每天、每周或每月)。
3.结合元数据存储库备份:在备份脚本中,考虑将元数据存储库的备份作为一部分。这样可以同时备份表结构的定义和元信息,提供更全面的恢复能力。结合元数据存储库备份:在备份脚本中,考虑将元数据存储库的备份作为一部分。这样可以同时备份表结构的定义和元信息,提供更全面的恢复能力。
下面是一个自动备份hive表结构的shell脚本示例:

方式三:解析Hive元数据,备份数据
这个方法比较适合大规模集群下,对hive表结构的备份,特别是那种库表有几万,几十万张的规模,使用此种方式不会损耗现有集群的性能。
思路上是通过获取hive元数据的数据,抽取每张表的结构信息,这里在结合shell 处理组合成完整的建表语句;
Hive元数据信息对应MySQL数据库表可以参考这个文章
大概的执行步骤如下:通过sql取表结构信息,具体sql如下:
借助shell,搞一个脚本文件,执行直接输出建表 语句,类似下面;(代码这里没有贴出来,有需要的私聊)
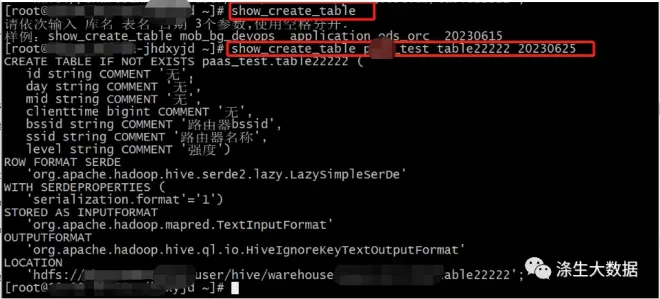
这样后期有表被误删除,需要查看备份的表结构,直接通过执行shell 指令就可以查看了。
当然为了更方便的查看,还可以基于此,结合grafana做可视化的查询展示,大概的实现如下;
这里要利用grafana的一个json插件,这样可以可以自定义一个接口服务,将数据以json的形式返回到grafana即可展示;
实现的效果如下:

注:本文可以结合 chatgpt助力大数据数仓开发实践,效果惊艳 使用,以此来恢复线上无删除的表结构,非常实用!!!
涤生大数据往期精彩推荐
1.涤生大数据教学集群的首次运维现场复现
2.涤生大数据HDFS小文件治理总结
3.运维实战:DolphinScheduler 生产环境升级
4.运维实战:Ambari开发手册-DolphinScheduler集成实操
5.大数据运维实战之Ambari修护Hive无法更换tez引擎
