
百度新突破!商业可行性已验证!EgoVM:轻量级矢量化地图解析~
作者:大森林 | 来源:3D视觉工坊
在公众号「3D视觉工坊」后台,回复「原论文」可获取论文pdf。
添加微信:dddvisiona,备注:自动驾驶,拉你入群。文末附行业细分群。
EgoVM是一种端到端网络,它使用轻量级矢量化地图来实现精确的自我定位。它从在线多视图图像和LiDAR点云中提取鸟瞰视图(BEV)特征,并采用可学习的语义嵌入来编码地图元素的语义类型。然后,它通过语义分割来监督这些特征与BEV特征的一致性。该方法还使用Transformer解码器进行跨模态匹配,并采用高鲁棒性的基于直方图的姿态解算器来确定最佳姿态偏移。实验结果表明,该方法在厘米级定位精度方面表现出色,并且优于使用点云地图的现有方法。此外,该本方法已在各种复杂城市场景下的大型自动驾驶车队中进行了广泛测试,验证了其在商业上的可行性。这里也推荐「3D视觉工坊」新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。
精确可靠的自我定位对自动驾驶至关重要。在本文中,我们提出了EgoVM,它采用了一种端到端的定位网络,它实现了与先前最先进方法相当的定位精度,但使用轻量级矢量化地图而不是笨重的基于点的地图。首先,我们实时地从多视图图像和激光雷达点云中提取鸟瞰视角(BEV)特征。然后,我们利用一组可学习的语义嵌入来对地图元素的语义类型进行编码,并通过语义分割进行监督学习,以实现它们的特征表示与BEV特征的对齐。接着,我们将由可学习的语义嵌入和地图元素的坐标组成的地图查询馈送到转换器解码器中,来与BEV特征进行跨模态匹配。最后,我们使用一个稳健的基于直方图的姿态求解器,在候选姿态空间中进行搜索,以估计最佳姿态。我们在nuScenes数据集和自行收集的数据集上对我们方法的有效性进行了全面验证。实验结果表明,我们的方法实现了厘米级定位精度,并且显著优于基于矢量化地图的现有方法。此外,我们的模型已经在大规模的自动驾驶车队中进行了广泛测试,覆盖了各种具有挑战性的城市场景。

图1. 我们方法的框架图。(a) 输入包括多视图图像、激光雷达点云和矢量化地图。(b) BEV特征提取模块提取BEV特征,然后与矢量化地图进行交互以生成地图嵌入。© 姿态求解模块以BEV特征和地图嵌入为输入,实现厘米级定位。
给定在线点云、多视图图像、预构建的矢量化地图以及初始姿态,我们的目标是估计相对于初始姿态的最佳姿态偏移量。预构建的地图包含诸如车道线、人行横道、停车线、车道标记、交通标志和杆等矢量化元素,表示为,其中是第i个矢量化地图元素。具体来说,车道线、道路边界和停车线在鸟瞰平面上表示为端点()的水平线段。人行横道表示为相邻端点() 的多边形段。交通标志和杆矢量化为(x,y,0,h),其中(x,y)和h分别是中心点和高度。我们的模型还需要一个初始姿态作为输入,它可以由多传感器融合定位系统提供。估计的姿态偏移量仅由2D水平偏移和航向偏移组成,表示为。
EgoVM由三部分组成。首先,我们将多视图图像特征和激光雷达鸟瞰视角特征提取并融合,得到统一的鸟瞰视角特征(第3.1节)。其次,我们使用一组可学习的嵌入来对地图元素类型进行编码,并在Transformer解码器的监督下,让它们与鸟瞰视角特征进行交互,从而生成地图嵌入(第3.2节)。第三,我们利用姿态求解器对几个候选姿态进行采样,并将地图元素投影到鸟瞰平面上。然后,我们通过双线性插值获取相应的特征,并将它们与地图嵌入进行比较,以估计最佳姿态偏移量(第3.3节)。

图2. EgoVM的网络结构。首先,多视图图像和3D激光雷达点被分别馈送到摄像头编码器和激光雷达编码器中,并融合以获得BEV特征。其次,矢量化地图元素和BEV特征用作Transformer解码器的查询和键值,进行跨模态匹配,从而生成地图嵌入。第三,姿态求解器对若干候选姿态进行采样,以投影地图元素并计算它们的相似度,从而估计最佳姿态偏移量。
我们使用Transformer解码器来实现图像特征和激光雷达鸟瞰视角特征的融合。首先,我们将多视图图像和激光雷达点分别输入到摄像头编码器和激光雷达编码器中,以提取图像特征和激光雷达鸟瞰视角特征。然后,我们利用Transformer解码器,以激光雷达鸟瞰视角特征作为初始的鸟瞰视角查询,并让它们与图像特征进行交互,从而得到融合的鸟瞰视角特征。
摄像头编码器。多视图图像被馈送到一个共享的backbone网络中,后接FPN提取多尺度特征,表示为,其中是第i个摄像头的第j级特征,分别是第j级特征的高度和宽度。
激光雷达编码器。3D激光雷达点首先被馈送到一个基于pillar的特征提取器中提取伪图像特征。然后,一组2D卷积层被应用于从伪图像特征中获得激光雷达鸟瞰视角特征,其中和分别是鸟瞰空间的高度和宽度。
鸟瞰视角融合。为生成统一的激光雷达-摄像头鸟瞰视角特征,我们采用Transformer解码器基于鸟瞰视角进行激光雷达鸟瞰视角特征和多视图图像特征的融合。具体来说,我们使用激光雷达鸟瞰视角特征来初始化鸟瞰视角查询,对它们执行自注意力,然后应用交叉注意力来聚合多视图图像特征。自注意力层和交叉注意力层基于可变形注意力来实现高效率。融合的鸟瞰视角特征表示为。
矢量化地图元素在表示上与鸟瞰视角特征差别很大。为了匹配它们,我们采用一组可学习的嵌入和一个Transformer解码器来弥合表示鸿沟。可学习的嵌入对地图元素的语义类型进行编码,然后作为查询为Transformer解码器与鸟瞰视角特征进行交互,生成地图元素的统一特征,称为地图嵌入。
语义嵌入。矢量化地图元素具有不同的语义类型,例如车道线、道路边界、停车线、人行横道、车道标记、杆和交通标志。我们使用一组可学习的嵌入,每个嵌入期望学习对应语义类型的特定表示。每个地图元素具有语义类型,相应的语义嵌入是。
位置编码。矢量化地图元素通常以全局坐标系统(如UTM坐标系)表示。首先,我们通过

将它们归一化,其中是初始姿态坐标,是鸟瞰空间的高度和宽度范围。
然后,我们将归一化的地图元素馈送到一个共享的多层感知机(MLP)层以获得位置编码。
匹配。我们应用一个Transformer解码器来匹配地图元素与鸟瞰视角特征,得到地图嵌入。我们通过添加其语义嵌入和位置编码来初始化地图查询:

Transformer解码器的自注意力模块形式化为:

其中M是头数,和是可学习的投影矩阵,是地图查询和之间的注意力权重。交叉注意力模块定义为:

其中DA表示可变形注意力,是通过初始姿态将地图元素的端点投影到鸟瞰平面获得的参考点,是鸟瞰空间的2D位置编码。
语义监督。为了更好地学习语义嵌入,我们使用一个辅助网络执行语义分割。我们以第j个语义类型为例。给定鸟瞰视角特征,第j个语义类型的语义概率定义为:

其中和分别是鸟瞰网格的索引,表示点积。
为每个语义类型生成真实语义概率,我们执行以下步骤。首先,我们使用真实姿态将地图元素投影到鸟瞰平面。其次,我们将鸟瞰平面划分为大小的网格,根据网格是否被地图元素占用分配0或1,得到表示第个语义类型的真实语义概率的二值矩阵。
姿态求解器。在x、y和航向尺度上通过网格搜索对姿态偏移量进行采样,表示为,然后通过将初始姿态与它们组合生成候选姿态。
最佳姿态偏移量。我们使用特定的候选姿态将地图元素投影到鸟瞰平面以获得它们的鸟瞰视角特征,通过在融合的鸟瞰视角特征上进行双线性插值。然后我们计算和地图嵌入在候选姿态下的相似度分数,通过

其中是的地图嵌入,是一个共享的MLP。然后,我们通过softmax将所有候选姿态的相似度分数归一化为后验概率,其中。最后,我们估计姿态偏移量和协方差:

RMSE损失。我们定义第一个损失为预测姿态偏移量与真实偏移量之间的均方根误差(RMSE):

其中,是通过规范化的对角线元素获得的对角矩阵。
姿态求解器KL损失。第二个损失源自于Kullback-Leibler(KL)散度,其目的是正则化后验概率分布。舍弃KL散度的常数项后,可以获得KL损失:

其中和分别表示目标概率分布和似然函数。注意,在第3.3节中定义。
我们定义,其中是狄拉克delta函数。方程10重写为:

基于此,可以通过蒙特卡洛积分获得姿态求解器KL损失:

随机姿态KL损失。我们使用随机姿态采样策略进一步增强监督。采样姿态从姿态分布中绘制,KL损失计算如下:

其中是x和y维度上2自由度的多变量t分布与航向维度上von Mises分布和均匀分布的混合。
语义分割损失。我们使用对所有语义类求和的局部损失(FC)作为语义分割损失函数来更好地监督语义嵌入和鸟瞰视角特征:
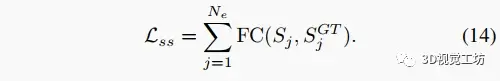
矢量化地图由外观特征(如车道线、车道标记、停车线和人行横道)和几何特征(如杆和交通标志)组成。仅依赖外观特征的定位在低光条件下容易退化。几何特征可以帮助提高定位性能,但是它们在每个路段都很稀疏且不可用。因此,我们提出使用surfels,这是场景中丰富的平面特征,来增强地图中的几何特征。我们将surfels表示为,其中是中心点,是法向量,,是surfels的协方差矩阵的特征值。Surfels非常丰富且对定位有利,但是处理它们所有surfels非常低效。因此,我们应用特征值和网格采样滤波器来减少surfels的数量,通过丢弃满足的surfels,并在每个1m网格中只保留一个具有最小的surfel。与其他矢量化地图元素一样,surfels涉及跨模态匹配模块与鸟瞰视角特征进行交互,以及姿态求解模块来估计姿态。这里也推荐「3D视觉工坊」新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。
我们对我们的模型进行了全面的分析和评估。我们使用nuScenes数据集和自行收集的数据集进行了广泛的实验验证。在准确性评估方面,与其他使用向量化地图的方法相比,提出的方法在厘米级定位精度方面表现出色,并取得了显著的优势。此外,本方法在大规模自动驾驶车辆中的各种复杂城市场景下进行了广泛测试,并取得了令人满意的结果。消融实验删除了地图中的某些特定类型的地标,并评估了每个组件的影响。结果表明,方法中的关键组件对于定位精度的提升起到了重要作用,并且直方图式姿态解算器的效果明显优于回归式解算器。本方法在运行时间分析中也得到了评估,结果显示本方法满足实时定位的要求,并且相较于其他方法具有更稳定的推断时间。

表1. 在自行收集的数据集上与其他方法比较定位精度,使用纵向、横向和航向误差作为评价指标。加粗下和划线分别表示最好和第二好的结果。附带上标*表示与我们方法相比显著更高,附带下标*表示与我们方法相比显著更低。

表2. 在nuScenes数据集上评估定位精度。

表3. 比较不同方法建立地图内存大小。

表4. 在自行收集并增强的数据集上进行消融实验分析来我们方法的关键组件。

图3. 可视化三个不同场景的结果。最左边的列显示不同场景的前视图图像,其余列描绘消融实验和我们方法两种模式的BEV特征。
我们提出了EgoVM,它是一种新颖的端到端定位网络,它可以使用轻量级矢量化地图在各种具有挑战性的城市场景中提高定位精度至厘米级。我们设计了一个跨模态匹配模块,它由一个受语义分割监督的可学习语义嵌入和一个Transformer解码器组成,通过将两个输入模态转化为统一表示来增强匹配性能。此外,我们还结合了激光雷达几何特征来进一步提高定位性能,这弥补了某些场景中外观特征的不足。我们将我们的模型与GNSS和IMU传感器集成,形成了一个多传感器融合定位系统,并已将其部署到大规模的自动驾驶车队,展示了其在商业上的可行性。
3D视觉细分群成立啦!
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向。
细分群包括:
[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;
[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;
[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。
[三维重建方向]NeRF、colmap、OpenMVS、MVSNet等。
[无人机方向]四旋翼建模、无人机飞控等。
除了这些,还有求职、硬件选型、视觉产品落地等交流群。
大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群
