
共识机制-POW、POS、DPOS、PBFT、RAFT
【搜集了CSDN的很多篇文章整理的】
共识机制
布式一致性 (distributed consensus) 是分布式系统中最基本的问题,用来保证一个分布式系统的可靠性以及容错能力。简单来说,分布式一致性是指多个服务器的保持状态一致。
在分布式系统中,可能出现各种意外(断电、网络拥塞、CPU/内存耗尽等等),使得服务器宕机或无法访问,最终导致无法和其他服务器保持状态一致。为了应对这种情况,就需要有一种一致性协议来进行容错,使得分布式系统中即使有部分服务器宕机或无法访问,整体依然可以对外提供服务。
复制状态机
复制状态机(Replicated State Machines)是指一组服务器上的状态机产生相同状态的副本,并且在一些机器宕掉的情况下也可以继续运行。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
复制状态机通常都是基于复制日志实现的。每一个服务器存储一个包含一系列指令的日志,并且按照日志的顺序进行执行。每一个日志都按照相同的顺序包含相同的指令,所以每一个服务器都执行相同的指令序列。因为每个状态机都是确定的,每一次执行操作都产生相同的状态和同样的序列。
保证复制日志相同就是一致性算法的工作了。在一台服务器上,一致性模块接收客户端发送来的指令然后增加到自己的日志中去。它和其他服务器上的一致性模块进行通信来保证每一个服务器上的日志最终都以相同的顺序包含相同的请求,尽管有些服务器会宕机。一旦指令被正确的复制,每一个服务器的状态机按照日志顺序处理他们,然后输出结果被返回给客户端。因此,服务器集群看起来形成一个高可靠的状态机。
实际系统中使用的一致性算法通常含有以下特性:
①安全性保证(绝对不会返回一个错误的结果):在非拜占庭错误情况下,包括网络延迟、分区、丢包、冗余和乱序等错误都可以保证正确。
②可用性:集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用。
③不依赖时序来保证一致性:物理时钟错误或者极端的消息延迟只有在最坏情况下才会导致可用性问题。
通常情况下,一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能。
一、Raft
Raft算法是目前使用最广泛的非拜占庭容错类共识算法。Raft算法主要依靠投票机制和日志复制机制来实现节点间的共识。节点通过投票选出一个leader,由leader负责处理所有请求,再将请求以日志的方式复制到其他节点。
Raft保证了在一个由N个节点构成的系统中有(N+1)/2(向上取整)个节点正常工作的情况下的系统的一致性。
Raft 是一种为了管理日志复制的分布式一致性算法。Raft出现之前,Paxos一直是分布式一致性算法的标准。Paxos难以理解,更难以实现。Raft的设计目标是简化Paxos。
Raft 可以解决分布式 CAP 理论中的CP,即一致性(C:Consistency)和分区容忍性(P:Partition Tolerance),并不能解决可用性(A:Availability)的问题。
1、身份
每个网络节点只能如下三种身份之一:Leader、Follower以及Candidate。
Leader:主要负责与外界交互,由Follower节点选举,在每一次共识过程中有且仅有一个Leader节点,由Leader全权负责从交易池中取出交易、打包交易组成区块并将区块上链;
Follower:以Leader节点为准进行同步,并在Leader节点失效时举行选举以选出新的Leader节点;
Candidate:Follower节点在竞选Leader时拥有的临时身份。
2、任期
Raft算法将时间划分为不定长度的任期Terms,Terms为连续的数字。每个Term以选举开始,如果选举成功,则由当前leader负责出块,如果选举失败,并没有选举出新的单一Leader,则会开启新的Term,重新开始选举。
3、PRC
Raft 算法中服务器节点之间通信使用远程过程调用(RPC),并且基本的一致性算法只需要两种类型的 RPC,为了在服务器之间传输快照增加了第三种 RPC。
【RPC有三种】:
RequestVote RPC:候选人在选举期间发起。
AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成。
InstallSnapshot RPC: 领导者使用该RPC来发送快照给太落后的追随者。
4、leader 选举
Raft共识模块中使用心跳机制来触发Leader选举。当节点启动时,节点自动成为Follower且将Term置0。只要Follower从Leader或者Candidate收到有效的Heartbeat或RequestVote消息,其就会保持在Follower状态,如果Follower在一段时间内(这段时间称为 Election Timeout)没收到上述消息,则它会假设系统当前的Leader已经失活,然后增加自己的Term并转换为Candidiate,开启新一轮的Leader选举流程,流程如下:
(1)Follower增加当前的Term,转换为Candidate;
(2)Candidate将票投给自己,并广播RequestVote到其他节点请求投票;
(3)Candidate节点保持在Candidate状态,直到下面三种情况中的一种发生:
①该节点赢得选举,即获得了超过半数以上的服务器投票,成为 Leader;
②在等待选举期间,Candidate收到了其他节点的Heartbeat,有其他节点获得了半数以上的投票;
③经过Election Timeout后,没有Leader被选出。
Raft算法采用随机定时器的方法来避免节点选票出现平均瓜分的情况以保证大多数时候只会有一个节点超时进入Candidate状态并获得大部分节点的投票成为Leader。
4.1投票流程
节点在收到VoteReq消息后,会根据消息的内容选择不同的响应策略:
(1)VoteReq的Term小于或等于自己的Term
①如果节点是Leader,则拒绝该投票请求,Candidate收到此响应【拒绝】后会放弃选举转变为Follower,并增加投票超时;
②如果节点不是Leader:
若<,则拒绝该投票请求,如果Candidate收到超过半数的该种响应(被拒绝)则表明其已经过时,此时Candidate会放弃选举转变为Follower,并增加投票超时;
若=,则拒绝该投票请求,对于该投票请求不作任何处理。对于每个节点而言,只能按照先到先得的原则投票给一个Candidate,从而保证每轮选举中至多只有一个Candidate被选为Leader。
(2)VoteReq的lastLeaderTerm小于自己的lastLeaderTerm
每个节点中会有一个lastLeaderTerm字段表示该节点见过的最后一个Leader的Term,lastLeaderTerm仅能由Heartbeat进行更新。如果VoteReq中的lastLeaderTerm小于自己的lastLeaderTerm,表明Leader访问这个Candidate存在问题,如果此时Candidate处于网络孤岛的环境中,会不断向外提起投票请求,因此需要打断它的投票请求,所以此时节点会拒绝该投票请求。
(3)VoteReq的lastBlockNumber小于自己的lastBlockNumber
每个节点中会有一个lastBlockNumber字段表示节点见到过的最新块的块高。在出块过程中,节点间会进行区块复制,在区块复制的过程中,可能有部分节点收到了较新的区块数据而部分没有,从而导致不同节点的lastBlockNumber不一致。为了使系统能够达成一致,需要要求节点必须把票投给拥有较新数据的节点,因此在这种情况下节点会拒绝该投票请求。
(4)节点是第一次投票
为了避免出现Follower因为网络抖动导致重新发起选举,规定如果节点是第一次投票,直接拒绝该投票请求,同时会将自己的firstVote字段置为该Candidate的节点索引。
(5)1~4步骤中都没有拒绝投票请求
同意该投票请求。
4.2 心跳超时
在Leader成为网络孤岛时,Leader可以发出心跳、Follower可以收到心跳但是Leader收不到心跳回应,这种情况下Leader此时已经出现网络异常,但是由于一直可以向外发送心跳包会导致Follower无法切换状态进行选取,系统陷入停滞。为了避免第二种情况发生,模块中设置了心跳超时机制,Leader每次收到心跳回应时会进行相应记录,一旦一段时间后记录没有更新则Leader放弃Leader身份并转换为Follower节点。
5、Leader选举的限制
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。所有的日志条目都只会从Leader节点往Follower节点写入,且Leader节点上的日志只会增加,绝对不会删除或者覆盖。
这意味着Leader节点必须包含所有已经提交的日志,即能被选举为Leader的节点一定需要包含所有的已经提交的日志【Leader选举的限制】。因为日志只会从Leader向Follower传输,所以如果被选举出的Leader缺少已经Commit的日志,那么这些已经提交的日志就会丢失,显然这是不符合要求的。
6、日志复制(保证数据一致性)
6.1 日志复制的过程
当Client向集群Leader节点提交数据后,Leader节点接收到的数据处于未提交状态,
接着Leader节点会并发向所有Follower节点复制数据并等待接收响应,确保至少集群中超过半数节点已接收到数据后再向 Client 确认数据已接收。一旦向Client发出数据接收Ack响应后,表明此时数据状态进入已提交(Committed),Leader节点再向Follower节点发通知告知该数据状态已提交。
leader接受客户端的请求 → 作为日志条目(Log entries)加入自己的日志中 → 并行向其他服务器发起AppendEntries PRC复制日志条目 → 被大多是服务器复制 → leader将日志应用到自己的状态机上,并向客户端返回执行结果。
①客户端的每一个请求都包含被复制状态机执行的指令。
②leader把这个指令作为一条新的日志条目添加到日志中,然后并行发起 RPC 给其他的服务器,让他们复制这条信息。
③假如这条日志被安全的复制,领导人就应用这条日志到自己的状态机中,并返回给客户端。
④如果follower宕机/运行缓慢/丢包,leader会不断的重试,直到所有的follower最终都复制了所有的日志条目。

leader选举的过程是:①增加term号;②给自己投票;③重置选举超时计时器;④发送请求投票的RPC给其它节点。
6.2 日志的组成
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term)和用于状态机执行的命令。如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。

上图显示,共有 8 条日志,提交了 7 条。提交的日志都将通过状态机持久化到磁盘中,防止宕机。
6.3 日志的一致性

(1)日志复制的两条保证
如果不同日志中的两个条目有着相同的索引和任期号,则它们
①所存储的命令是相同的(原因:leader 最多在一个任期里的一个日志索引位置创建一条日志条目,日志条目在日志的位置从来不会改变)。
②之前的所有条目都是完全一样的(原因:每次RPC发送附加日志时,leader会把这条日志条目的前面的日志的下标和任期号一起发送给 follower,如果 follower 发现和自己的日志不匹配,那么就拒绝接受这条日志,这个称之为一致性检查)。
(2)日志的不正常情况
一般情况下,Leader和Followers的日志保持一致,因此AppendEntries一致性检查通常不会失败。然而,Leader崩溃可能会导致日志不一致:旧的Leader可能没有完全复制完日志中的所有条目。
下图阐述了一些Followers可能和新的Leader日志不同的情况。一个Follower可能会丢失掉Leader上的一些条目,也有可能包含一些Leader没有的条目,也有可能两者都会发生。丢失的或者多出来的条目可能会持续多个任期。

Leader通过强制Followers复制它的日志来处理日志的不一致,Followers上的不一致的日志会被Leader的日志覆盖。
Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致位置点(基于上述的两条保证),然后向后逐条覆盖Followers在该位置之后的条目。这样就实现了主从日志的一致性。
7、安全性
Raft增加了如下两条限制以保证安全性:
①拥有最新的已提交的log entry的Follower才有资格成为leader。
②Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index小于commit index的日志被间接提交)。

上图:解释了为什么 Leader 无法对旧 Term 的日志条目进行提交。
(a):S1是Leader,且S1写入日志条目为 (Term 2,日志索引 2),只有S2复制了这个日志条目。
(b):S1下线,S5被选举为Term3的Leader。S5 写入日志条目为 (Term 3,日志索引 2)。
(c):S5下线,S1被选举为 Term4 的 Leader。此时,Term 2的那条日志条目已经被复制到了集群中的大多数节点上,但是还没有被提交。
(d):S1下线,S5被重新选举为 Term3 的 Leader。然后S5覆盖了日志索引2处的日志。
(e):若 (d) 还未发生,即S1再次下线之前,S1把自己主导的日志条目复制到了大多数节点上,则后续Term里这些新日志条目就会被提交。这样在同一时刻就同时保证了之前的所有旧日志条目就会被提交。
8、日志压缩
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft采用对整个系统进行snapshot来解决,snapshot之前的日志都可以丢弃(以前的数据已经落盘了)。
每个副本独立的对自己的系统状态进行snapshot,并且只能对已经提交的日志记录进行snapshot。

【Snapshot中包含以下内容】:
①日志元数据,最后一条已提交的log entry的log index和term。这两个值在snapshot之后的第一条log entry的AppendEntries RPC的完整性检查的时候会被用上。
②系统当前状态。
当Leader要发给某个日志落后太多的Follower的log entry被丢弃,Leader会将snapshot发给Follower。或者当新加进一台机器时,也会发送snapshot给它。发送snapshot使用InstalledSnapshot RPC。
推荐当日志达到某个固定的大小做一次snapshot。
①太频繁,消耗磁盘带宽;
②太不频繁,节点重启需要回放大量日志,影响可用性。
做一次snapshot可能耗时过长,会影响正常日志同步。可以通过使用copy-on-write技术避免snapshot过程影响正常日志同步。
9、成员变更
9.1 常规处理成员变更存在的问题
我们先将成员变更请求当成普通的写请求,由领导者得到多数节点响应后,每个节点提交成员变更日志,将从旧成员配置(Cold)切换到新成员配置(Cnew)。但每个节点提交成员变更日志的时刻可能不同,这将造成各个服务器切换配置的时刻也不同,这就有可能选出两个领导者,破坏安全性。
考虑以下这种情况:集群配额从3台机器变成了5台,可能存在这样的一个时间点,两个不同的领导者在同一个任期里都可以被选举成功(双主问题),一个是通过旧的配置,一个通过新的配置。
简而言之,成员变更存在的问题是增加或者减少的成员太多了,导致旧成员组和新成员组没有交集,因此出现了双主。
9.2 解决方案之一阶段成员变更
Raft解决方法是每次成员变更只允许增加或删除一个成员(如果要变更多个成员,连续变更多次)。
10、问题
①Raft主要是分为leader选举、日志复制、日志压缩、成员变更等。
②Raft网络分区下的数据一致性怎么解决?
发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwer了,那么Leader只能正常更新它能访问的那些Follower,而大多数的Follower因为没有了Leader,他们重新选出一个Leader,然后这个 Leader来接受客户端的请求,如果客户端要求其添加新的日志,这个新的Leader会通知大多数Follower。如果这时网络故障修复了,原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新(递减查询匹配日志)。
③Raft和Paxos的区别和优缺点?
Raft的leader有限制,拥有最新日志的节点才能成为leader,multi-paxos中对成为Leader的限制比较低,任何节点都可以成为leader。
Raft中Leader在每一个任期都有Term号。
④Raft prevote机制?
Prevote(预投票)是一个类似于两阶段提交的协议,第一阶段先征求其他节点是否同意选举,如果同意选举则发起真正的选举操作,否则降为Follower角色。这样就避免了网络分区节点重新加入集群,触发不必要的选举操作。
⑤Raft里面怎么保证数据被commit,leader宕机了会怎样,之前的没提交的数据会怎样?
leader会通过RPC向follower发出日志复制,等待所有的follower复制完成,这个过程是阻塞的。
老的leader里面没提交的数据会回滚,然后同步新leader的数据。
⑥Raft里面的lease机制是什么,有什么作用?
租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。中心思想是每次租约时长内只有一个节点获得租约、到期后必须重新颁发租约。

假设我们有租约颁发节点Z,节点0、1和z竞选leader,租约过程如下:
(a).节点0、1、2在Z上注册自己,Z根据一定的规则(例如先到先得)颁发租约给节点,该租约同时对应一个有效时长;这里假设节点0获得租约、成为leader
(b).leader宕机时,只有租约到期(timeout)后才重新发起选举,这里节点1获得租约、成为leader
二、PBFT
结论:时间复杂度是O(n^2),可解决拜占庭问题。PBFT算法可以容忍小于1/3个无效或者恶意节点。如果系统内有n台机子,那么系统最多能容忍的作恶/故障节点为(n-1)/3个。系统的总节点数为:|R| = 3f + 1。
优点: 算法的可靠性有严格的数学证明,具备(n-1)/3容错性。
缺点:当有1/3或以上记账人停止工作后,系统将无法提供服务。
证明过程:我们知道有f个作恶节点,且无法预测这f个作恶节点做了什么(错误消息/不发送),并不知道这n-f个里面有几个是作恶节点,我们必须保证正常的节点大于作恶节点数。所以有 n-f-f > f,从而得出了n > 3f。
主节点确定机制:主节点通过视图编号以及节点数集合来确定,即:主节点 p = v mod |R|。v:视图编号,|R|节点个数,p:主节点编号。
PBFT算法有两个限定条件:
①所有节点必须是确定性的,即:在给定状态和参数相同的情况下,操作执行的结果必须相同。
②所有节点必须从相同的状态开始执行。
在这两个限定条件下,即使失效的副本节点存在,PBFT算法对所有非失效副本节点的请求执行总顺序达成一致,从而保证安全性。
1、角色划分
Client: 客户端节点,负责发送交易请求。
Primary: 主节点,负责将交易打包成区块和区块共识,每轮共识过程有且仅有一个。
Replica: 副本节点,负责区块共识,每轮共识过程中有多个Replica节点。
其中,Primary和Replica节点都属于共识节点。
2、基本流程
请求阶段:客户端将交易信息向全网节点广播,生成主节点负责验证请求信息,并生成预准备消息
预准备阶段:主节点广播预准备消息
准备阶段:每个节点接收到消息后进行验证,并将验证结果消息发送给全部其他的节点
确认阶段:若系统承受的最大恶意节点数为f,则当某节点收到2f条来自其他节点的确认消息后,加上自己的确认消息,总数达到(2f+1)条时,可以向全网发送一条广播消息。
响应阶段:PBFT算法是强一致性算法,每次区块的产出都是由唯一的主节点主导生成,不存在分叉的可能性,但容错率显著低于比特币的51%可靠性;
3、核心流程
算法的核心三个阶段:pre-prepare (预准备),prepare (准备), commit (提交)。

图中的C代表客户端,0,1,2,3 代表节点的编号,其中0 是主节点primary,打×的3代表故障或作恶节点,这里表现的就是对其它节点的请求无响应。整个过程大致是如下:
首先,客户端向主节点0发起请求<<REQUEST,o,t,c>>其中t是时间戳,o表示操作,c是这个client,主节点收到客户端请求,会向其它节点发送 pre-prepare 消息,其它节点就收到了pre-prepare 消息,就开始了这个核心三阶段共识过程了。
(1)Pre-prepare 阶段
副本节点replica收到 pre-prepare 消息<<PRE_PREPARE,v,n,d>,m>后,判断是否接收该消息。其中,v 代表视图编号,n代表消息序号(主节点收到客户端的每个请求都以一个编号来标记),d代表消息摘要,m代表原始消息数据。消息里的 v 和 n 在之前收到的消息里出现过的,但d和m却和之前的消息不一致,或者请求编号n不在高低水位之间,这时候就会拒绝请求。拒绝的逻辑就是主节点不会发送两条具有相同的v和n,但d和m却不同的消息。
Replia节点接收到pre-prepare消息,进行以下消息验证:
①消息m的签名合法性,并且消息摘要d和消息m相匹配:d=hash(m)
②节点当前处于视图v中
③节点当前在同一个(view v ,sequence n)上没有其它pre-prepare消息,即不存在另外一个m’和对应的d’ ,d’=hash(m’)
④h<=n<=H,H和h代表序号n的高低水位。
(2)Prepare 阶段
当前节点同意请求后会向其它节点发送 prepare 消息<PREPARE,v,n,d,i>同时将消息记录到log中,其中 i表示当前节点的身份。同一时刻可能有 n 个节点也在进行这个过程。因此节点是有可能收到其它节点发送的 prepare 消息的,当前节点i验证这些prepare消息和自己发出的prepare消息的v,n,d三个数据是否都是一致的。验证通过之后,当前节点i将prepared(m,v,n) 设置为true,prepared(m,v,n) 代表共识节点认为在(v,n)中针对消息m的Prepare阶段是否已经完成。在一定时间范围内,如果收到超过 2f 个其他节点的prepare 消息,就代表 prepare 阶段已经完成。最后共识节点i发送commit消息并进入Commit阶段。
(3)Commit 阶段
当前节点i接收到2f个来自其他共识节点的commit消息<COMMIT,v,n,d,i>同时将该消息插入log中(算上自己的共有2f+1个),验证这些commit消息和自己发的commit消息的v,n,d三个数据都是一致后,共识节点将committed-local(m,v,n)设置为true,committed-local(m,v,n)代表共识节点确定消息m已经在整个系统中得到至少2f+1个节点的共识,而这保证了至少有f+1个non-faulty节点已经对消息m达成共识。于是节点就会执行请求,写入数据。
(4)Reply阶段
处理完毕后,节点会返回消息<<REPLY,v,t,c,i,r>>给客户端,其中v是视图编号,t是时间戳,i是副本的编号,r是请求执行的结果。当客户端收集到f+1个消息后,共识完成。
prepare和commit阶段为何都要2f+1个节点反馈确认?(这2f+1并不一定是相同的)
考虑最坏的情况:我们假设收到的有f个是正常节点发过来的,也有f个是恶意节点发过来的,那么,第2f+1个只可能是正常节点发过来的。由此可知,“大多数”正常的节点还是可以让系统工作下去的。所以2f+1这个参数和n>3f+1的要求是逻辑自洽的。
client为何只需要f+1个相同的回复就可确认?
考虑最坏的情况,我们假设这f+1个相同的reply中,有f个都是恶意节点。
所以至少有一个rely是正常节点发出来的,因为在prepare阶段,这个正常的节点已经可以保证prepared(m,v,n,i)为真,所以已经能代表大多数的意见,所以,client只需要f+1个相同的reply就能保证他拿到的是整个系统内“大多数正常节点“的意见,从而达到一致性。
总结: 如果顺利的话,一个节点收到1个pre-prepare消息和2f个和prepare消息进入commit阶段,2f+1个commit消息后可以reply给client,client收到f+1个回复就可以确认提交成功。
4、垃圾回收
根据前面的算法部分可以发现,我们需要不断地往log中插入消息,在view change时恢复需要用到。当某一request已经被f+1个正常节点执行完毕后,并当view change可以向其他节点证明当前状态的正确性,与该request相关的message就可以删除了。
当request的序号n % C (某一定值) =0时,产生一个checkpoint,节点i多播消息<<CHECKPOINT,n,d,i>>给其他节点,当节点接收2f+1个消息时,该checkpoint变为stable checkpoint,也就是这2f+1个节点可以证明该状态的正确性,同时可以删除序号≤n的消息相关的log信息和checkpoint信息。
checkpoint:当前节点处理的最新请求序号。
stable checkpoint (稳定检查点):是大部分节点 (2f+1个) 已经共识完成的最大请求序号。
高低水位:低水位就是stable checkpoint的序号n,高水位是n + K,其中K是定值,一般是C(上面提及到的某一定值)的整数倍。
具体过程:
执行K条请求后再向全网发起广播,告诉大家它已经将这K条执行完毕;如果大家反馈说这K条执行完毕,那就可以删除这K条的信息了;再执行K条,完成后再发起一次广播,即每隔K条发起一次全网共识,这个概念叫checkpoint,即每隔K条去征求一下大家的意见,要是获得了大多数的认同,就形成一个stable checkpoint(记录在第K条的编号)。
这是理想的情况,实际上当副本i向全网发出checkpoint共识后,其他节点可能没有执行完这K条请求,所以副本i不会立即得到响应,它还要继续自己的事情,那这个checkpoint在它那里就不是stable的。
这里有一个处理策略:对该副本来说,它的低水位h等于它上一个stable checkpoint的编号,高水位H=h+L(一般我们设置L是K的倍数,例如2倍),这样即使该副本处理速度很快,它处理的请求编号达到高水位H后也得停一停自己的脚步,直到它的stable checkpoint发生变化,它才能继续向前。
5、视图更换(view change):选举主节点的过程
当主节点出错或成为恶意节点时,就需要进行视图更换(view change),也就是选择(轮换法)下一个replica节点作为主节点,视图编号v进行+1操作,共识过程进入下一个view。
view change 会有三个阶段:view-change,view-change-ack ,new-view。
5.1触发条件
视图改变由以下两个条件之一触发:
①replica从一个client得知,primary存在不正当行为(例如:伪造数据等)
②replica不能收到primary发出的消息
View Change由replica发起,它们向其他副本发送IHatePrimary消息以启动一个视图改变。注意:View Chage不能由拜占庭节点发起。
5.2 VIEW-CHANGE的条件
Replica持续接收IHatePrimary消息,直到遇到下面两个条件之一:
①接收到超过f+1个IHatePrimary消息
②收到了其他节点的ViewChange消息。
将会将广播一条<VIEW-CHANGE, v+1, n, C, P, i>消息。
v:上一个视图编号
n:节点i的stable checkpoint的编号
C:2f+1个节点的有效checkpoint信息的集合
P:节点i中的上一个视图中编号大于n并且达到prepared状态的请求消息的集合
i:节点的编号
5.3. NEW-VIEW的条件
当前存活的节点编号最小的节点将成为新的主节点。当新的主节点收到 2f 个其它节点的 view-change 消息,则证明有足够多人的节点认为主节点有问题,于是就会向其它节点广播 new-view 消息<<NEW-VIEW,v+1,V,O>>
v:上一个视图编号
V:新的主节点接收到的有效的视图编号为v+1的view-change消息集合
O:pre-prepare消息的集合。假设 O 集合里消息的编号范围:(min~max), Min 为 V 集合最小的 stable checkpoint , Max 为 V 集合中最大序号的 prepare 消息。最后一步执行 O 集合里的 pre-preapare消息,每条消息会有两种情况: 若max-min>0,产生消息 <<pre-prepare,v+1,n,d>> ;若=0,产生消息 <<pre-prepare,v+1,n,d(null)>>
注意:replica节点不会发起new-view事件。对于主节点,发送new-view消息后会继续执行上个视图未处理完的请求,从pre-prepare阶段开始。其它节点验证new-view消息通过后,就会处理主节点发来的pre-prepare消息,这时执行的过程就是前面描述的PBFT过程。到这时,正式进入v+1(视图编号加1)的时代了。


PBFT共识算法:BFT类算法,可容忍≤三分之一的故障和作恶节点,可达到最终一致性;
Raft共识算法:CFT类算法,可容忍—半故障节点,不能防止节点作恶,可达到一致性。
三、POW:(Proof of Work)工作量证明机制
基本原理:付出多少工作量,就会获得多少报酬(比特币等加密货币)。“劳动”就是你为网络提供的计算服务(算力*时长),提供这种服务的过程就是“挖矿”。
优点:
①机制很复杂,但有很多细节:挖矿难度自动调整、区块奖励逐步减半等。
②理想状态,可以吸引很多用户参与其中,特别是越先参与的获得越多,会促使加密货币的初始阶段发展迅速,节点网络迅速扩大。
③通过“挖矿”的方式发行新币,把比特币分散给个人,实现了相对公平。
缺点:
①算力是计算机硬件(CPU、GPU等)提供的,要耗费电力,是对能源的直接消耗。
②算力的提供已经不再是单纯的CPU了,而是逐步发展到GPU、FPGA,乃至ASIC矿机。用户也从个人挖矿发展到大的矿池、矿场,算力集中越来越明显。这与去中心化的方向背道而驰,网络的安全逐渐受到威胁。
③比特币区块奖励每4年将减半,当挖矿的成本高于挖矿收益时,人们挖矿的积极性降低,会有大量算力减少,比特币网络的安全性进一步堪忧。
工作量证明系统主要特征是客户端需要做一定难度的工作得出一个结果,验证方却很容易通过结果来检查出客户端是不是做了相应的工作。【不对称】
举个例子,给定的一个基本的字符串"Hello, world!",给出的工作量要求是,在这个字符串后面添加一个叫做nonce的整数值,对变更后(添加nonce)的字符串进行SHA256哈希运算,如果得到的哈希结果(以16进制的形式表示)是以"0000"开头的,则验证通过。为了达到这个工作量证明的目标。需要不停的递增nonce值,对得到的新字符串进行SHA256哈希运算。按照这个规则,需要经过4251次计算才能找到恰好前4位为0的哈希散列。
比特币网络中任何一个节点,如果想生成一个新的区块并写入区块链,必须解出比特币网络出的工作量证明的迷题。
SHA是安全散列算法(Secure Hash Algorithm)的缩写,是一个密码散列函数家族。主要适用于数字签名标准。SHA256是输出值为256位的哈希算法。到目前为止,还没有出现对SHA256算法的有效攻击。
1、区块
区块头的大小为80字节:
4字节的版本号
32字节的上一个区块的散列值
32字节的Merkle Root Hash
4字节的时间缀(当前时间)
4字节的当前难度值
4字节的随机数
区块包含的交易列表则附加在区块头后面,其中的第一笔交易是coinbase交易,这是一笔为了让矿工获得奖励及手续费的特殊交易。

区块头,是用于比特币工作量证明的输入字符串。为了使区块头能体现区块所包含的所有交易,在区块的构造过程中,需要将该区块要包含的交易列表,通过Merkle Tree算法生成Merkle Root Hash,作为交易列表的摘要存到区块头中。
2、难度值
难度值(difficulty)是矿工们在挖矿时候的重要参考指标,它决定了矿工大约需要经过多少次哈希运算才能产生一个合法的区块。难度值必须根据全网算力的变化进行调整。难度的调整是在每个完整节点中独立自动发生的。每2016个区块,所有节点都会按统一的公式自动调整难度。
这个公式是由最新2016个区块的花费时长与期望时长比较得出的。
新难度值 = 旧难度值 * ( 过去2016个区块花费时长 / 20160 分钟 )
【撇开旧难度值,按比特币理想情况每10分钟出块的速度,过去11个块的总花费接近110分钟,这样,这个值永远趋近于1。】
工作量证明需要有一个目标值。比特币工作量证明的目标值(Target)的计算公式如下:
目标值 = 最大目标值 / 难度值
【最大目标值为一个恒定值】
0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
目标值的大小与难度值成反比。比特币工作量证明的达成就是矿工计算出来的区块哈希值必须小于目标值。
3、工作量证明的过程:
生成Coinbase交易,并与其他所有准备打包进区块的交易组成交易列表,通过Merkle Tree算法生成Merkle Root Hash
把Merkle Root Hash及其他相关字段组装成区块头,将区块头的80字节数据(Block Header)作为工作量证明的输入
不停的变更区块头中的随机数即nonce的数值【在0到232之间取值】,并对每次变更后的的区块头做双重SHA256运算(即SHA256(SHA256(Block_Header))),将结果值与当前网络的目标值做对比,如果小于目标值,则解题成功,工作量证明完成。
【Coinbase交易+其他交易 → 交易列表 → Merkle Root Hash →组装块头 → 作为工作量证明的输入 → 变更nonce → 双重SHA256运算 → 与目标值对比 → 小于,则成功。】
比特币PoW的过程,可以简单理解成就是将不同的nonce值作为输入,尝试进行SHA256哈希运算,找出满足给定数量前导0的哈希值的过程。而要求的前导0的个数越多,代表难度越大。
一般说来, PoW 共识的随机数搜索过程如下:
①搜集当前时间段的全网未确认交易, 并增加一个用于发行新比特币奖励的 Coinbase 交易, 形成当前区块体的交易集合;
②计算区块体交易集合的Merkle根记入区块头, 并填写区块头的其他元数据, 其中随机数 Nonce 置零;
③随机数 Nonce 加 1; 计算当前区块头的双 SHA256 哈希值, 如果小于或等于目标哈希值, 则成功搜索到合适的随机数并获得该区块的记账权; 否则继续步骤 3 直到任一节点搜索到合适的随机数 为止;
④如果一定时间内未成功, 则更新时间戳和未确认交易集合、重新计算 Merkle 根后继续搜索。
4、如何用PoW记账?
①客户端产生新的交易,向全网广播
②每个节点收到请求,将交易纳入区块中
③每个节点通过pow工作量证明
④当某个节点找到了证明,向全网广播
⑤当且仅当该区块的交易是有效的且之前未存在的,其他节点才认同该区块的有效性
⑥接受该区块且在该区块的末尾制造新的区块
大概时序图:

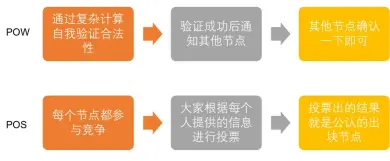
四、POS(Proof of Stake):股权证明机制。
基本原理:这是点点币(PPC)的创新。没有挖矿过程,在创世区块内写明了股权分配比例,之后通过转让、交易的方式(通常就是IPO),逐渐分散到用户手里,并通过“利息”的方式新增货币,实现对节点的奖励。以太坊是POW跟POS结合。
简单来说,就是一个根据用户持有货币的多少和时间(币龄),发放利息的一个制度。【使得难度与交易输人的币龄成反比】如果用户想获得更多的货币,那么就打开客户端,让它保持在线,就能通过获得“利息”获益,同时保证网络的安全。
实际上,点点币的权益证明机制结合了随机化与币龄的概念,未使用至少30天的币可以参与竞争下一区块,越久和越大的币集有更大的可能去签名下一区块。然而,一旦币的权益被用于签名一个区块, 则币龄将清为零,这样必须等待至少30日才能签署另一区块。
同时,为防止非常老或非常大的权益控制区块链,寻找下一区块的最大概率在90天后达到最大值,这一过程保护了网络,并随着时间逐渐生成新的币而无需消耗大量的计算能力。
点点币的开发者声称这将使得恶意攻击变得困难,因为没有中心化的挖矿池需求,而且购买半数以上的币的开销似乎超过获得51%的工作量证明的哈希计算能力。
权益证明必须采用某种方法定义任意区块链中的下一合法区块,依据账户结余来选择将导致中心化。为此,人们还设计了其他不同的方法来选择下一合法区块。
优点:
①节能。不用挖矿,不需要大量耗费电力和能源。
②更去中心化。相对于比特币等PoW类型的加密货币,PoS机制的加密货币对计算机硬件基本上没有过高要求,人人可挖矿(获得利息),不用担心算力集中导致中心化的出现(单用户通过购买获得51%的货币量,成本更高),网络更加安全有保障。
③避免紧缩。PoW机制的加密货币,因为用户丢失等各种原因,可能导致通货紧缩,但是PoS机制的加密货币按一定的年利率新增货币,可以有效避免紧缩出现,保持基本稳定。比特币之后,很多新币采用PoS机制,很多采用工作量证明机制的老币,也纷纷修改协议,“硬分叉”升级为PoS机制。
缺点:
①纯PoS机制的加密货币,只能通过IPO的方式发行,这就导致“少数人”(通常是开发者)获得大量成本极低的加密货币,在利益面前,很难保证他们不会大量抛售。
②PoS机制的加密货币,信用基础不够牢固。
为解决这个问题,很多采用PoW+PoS的双重机制,通过PoW挖矿发行加密货币,使用PoS维护网络稳定。或者采用DPoS机制,通过社区选举的方式,增强信任。
该算法与PoW算法的最大不同点在于区块的记账权由权益最高的节点获得, 而不是算力最高的节点。
共识过程中节点通过消耗的币龄来获取记账权,节点消耗的币龄越多,获得记账权的机会越大。算法设定的主链原则为:消耗币龄最多的链为系统中正确有效的链。点点币中 PoS算法合格区块的判定公式为:
ProofHash<Target×CoinAge
ProofHash对应一组数据的哈希,此处省略;
CoinAge为币龄(coin*age);
Target为当前目标值,同PoW一样,与难度成反比。
Target=PrevTarget×(1007×10×60+2×Tgap )/1009× 10×60
PrevTarget为上一个区块的目标值;
2×Tgap 为前两个区块的间隔时间。
当前两个区块时间间隔>10 min,当前目标值相比于上一个区块目标值会提高,即当前区块难度会降低;
当前两个区块时间间隔<10 min,当前目标值相比于上一个区块目标值会降低,即当前区块难度会提高。
PoS将算力竞争转化为权益竞争, 不仅节约算力, 权益的引入也能够防止节点发动恶意攻击; 同时促使所有节点有责任维护区块链的安全稳定运行以保障自身权益; PoS 虽然降低了算力资源的消耗, 但是没有解决中心化程度增强的问题, 新区块的生成趋向于权益高的节点。PoS中需要拥有超全网一半的权益发动51%攻击, 但其成本高于拥有超全网一半的算力,另外创建区块需要消耗权益, 使得PoS持续进行 51%攻击的难度增加, 一定程度上降低了 安全风险。
五、DPOS(Delegated Proof of Stake):授权股权证明机制
它是PoS的一种衍生算法,算法的思想是系统中持有权益的节点投票选举出一部分代表,再由这些代表轮流获取区块记账权,某种程度上类似于股份制公司的“董事会”。
基本原理:无人控制的公司发行股份,产生利润,并将利润分配给股东。实现这一切不需要信任任何人,因为每件事都是被硬编码到软件中的。通俗点讲就是:公司股份制,股东持有这些公司的股份,公司为股东产生回报,无需挖矿。
每个节点都可将自己持有的权益转化为选票投给自己信任的节点,所持的权益越多,选票所占的权重也就越高,获得票数最多的n个节点当选为见证人(代表)。见证人的名单每经过一个固定周期都将重新选举更换一次。见证人直接参与区块的共识和验证过程,在一个规定的时间内它们随机排列并轮流对交易进行打包,生成新区块连接到最长链上。每生成一个区块,见证人会获得m%的交易手续费,m值由见证人们提议设定并由选民们投票决议。参与见证人的竞选也需缴纳大量的保证金,这样,见证人在系统中投入的资金最大,为保证自身的利益积极地维护系统安全。
优点:
①能耗更低。DPoS机制将节点数量进一步减少到101个,在保证网络安全的前提下,整个网络的能耗进一步降低,网络运行成本最低。
②更加去中心化。目前,对于比特币而言,个人挖矿已经不现实了,比特币的算力都集中在几个大的矿池手里,每个矿池都是中心化的,就像DPoS的一个受托人,因此DPoS机制的加密货币更加去中心化。PoS机制的加密货币(比如未来币),要求用户开着客户端,事实上用户并不会天天开着电脑,因此真正的网络节点是由几个股东保持的,去中心化程度也不能与DPoS机制的加密货币相比。
③更快的确认速度。每个块的时间为10秒,一笔交易(在得到6-10个确认后)大概1分钟,一个完整的101个块的周期大概仅仅需要16分钟。而比特币(PoW机制)产生一个区块需要10分钟,一笔交易完成(6个区块确认后)需要1个小时。点点币(PoS机制)确认一笔交易大概也需要1小时。
缺点:
①投票的积极性并不高。绝大多数持股人(90%+)从未参与投票。这是因为投票需要时间、精力以及技能,而这恰恰是大多数投资者所缺乏的。
②对于坏节点的处理存在诸多困难。社区选举不能及时有效的阻止一些破坏节点的出现,给网络造成安全隐患。

POI:(Proof of Importance)重要度证明共识算法
基本原理:PoI使用账户重要性评分来分配记账权的概率。
优点:低能耗,速度快,公平
缺点:缺少社区共识,账户重要性≠设备贡献度
POP:(Proof of Participation)参与度证明
基本原理:这是标准链(CZR)的创新,POP 将 POI 和DPOS 的思想结合,既能确保对设备的公平性,又拥有社区的共识。
优点:低功耗、速度更快,更加安全,既能确保公平性,又拥有社区的共识。
POOL验证池
基于传统的分布式一致性技术,加上数据验证机制。
优点:不需要代币也可以工作,在成熟的分布式一致性算法(Pasox、Raft)基础上,实现秒级共识验证。
缺点:去中心化程度不如bictoin;更适合多方参与的多中心商业模式。
总结
POW(工作量证明机制):“按劳分配”。
POS(股权证明机制):持有的股票越多,权利越大 。
DPOS(授权股权证明机制):由大家选举产生董事会成员行使权利。
PBFT(实用拜占庭容错算法):一种基于消息传递的一致性算法,算法经过三个阶段:预准备(pre-prepare)、准备(prepare)、确认(commit)达成一致性,这些阶段可能因为失败而重复进行。
POI(重要度证明共识算法):本质是POS的变种。
POP(参与证明):前边所有的几种的升级。
POOL:国产的验证池
从机制设计上来看,POW 机制更加强调去中心, 更加强调对等。而DPOS 则是有一个明显的中心, 通过带来部分中心,来得到效率的提升。哪一种机制更好, 有待时间的验证。POW 已经运行快10年, 电力耗费已经非常严重。POP的出现, 有可能让记账这件事情更经济效率, 从而支撑起更多大规模的协作体系。

根据可容忍的故障类型的不同,可以将共识算法分为两类:
CFT类算法:容忍宕机错误类算法(crash fault tolerant consensus algorithm),可以容忍网络丢包、时钟漂移、部分节点宕机这种节点为良性的错误。常见算法有 Paxos、Raft。
BFT类算法:容忍拜占庭错误类算法(byzantine fault tolerant consensus algorithm),可以容忍部分节点任意类型错误,包括节点作恶的情况。常见算法有 PBFT、PoW、PoS等。
根据使用场景的不同,又可将共识算法分为公链共识、联盟链共识两类。
公链共识:公链的特点是节点数量多且分布分散,主要使用的共识算法有PoW和PoS,这两种共识的优点是可以支持的节点数量多,缺点是TPS较低和交易确认时间长。
联盟链共识:联盟链的特点是节点之间网络较为稳定且节点有准入要求,根据需要容忍的错误类型可以选择Raft和PBFT类算法,这类算法的优点是TPS较高且交易可以在毫秒级确认,缺点是支持的节点数量有限,通常不多于100个节点。
