
更加可靠和有效的近似最近邻搜索|SIGMOD 2023
摘要
本篇论文来自于 SIGMOD 2023,介绍了一种可靠和有效的距离比较操作的高维近似最近邻搜索。主要工作1.提出一种随机算法 ADSampling; 2.基于 ADSampling ,开发了两种算法特定的技术作为插件来增强现有的 AKNN 算法。
论文背景
提出问题:
在高维空间中,几乎所有 AKNN 算法的时间消耗都由距离比较操作(DCOs)所占据。对于每个操作,它扫描一个对象的全部维度,因此在维度上运行的时间是线性的。
解决方法:
提出了一种随机算法,名为 ADSampling,它在大多数距离比较操作(DCOs)中运行时间是对数级别,并且具有高概率成功。特点概括起来便是1. 缩短比较时间;2. 成功率高。
论文主要工作:
(1)提出一种随机算法 ADSampling;
(2)基于 ADSampling,我们开发了两种算法特定的技术作为插件来增强现有的AKNN算法。
其中,两种特定技术为:HNSW++和 IVF++。
HNSW++ 是基于 HNSW 算法的改进,通过使用更好的近似距离和更高效的候选生成策略来提高搜索速度。
IVF++ 是基于 IVF 算法的改进,通过重新组织数据布局和调整维度顺序来提高缓存友好性,从而减少内存访问开销,提高搜索速度。
传统方法:
1、FDScanning:计算对象的距离(从查询点),然后将计算的距离与阈值进行比较。(需要扫描对象的全部维度来执行操作)
2、PDScanning:增量扫描原始向量的维度,并在基于部分扫描的𝑑维度的距离(如下图公式)大于距离阈值𝑟时终止该过程。

ADSampling 核心:
将对象投影到具有不同维度的空间中,并基于投影向量进行比较操作(DCOs)以提高效率。
原理:对于远离查询的负对象来说,将它们投影到维数更少的空间就足以进行可靠的比较操作(DCOs); 而对于靠近查询的负对象,它们应该被投影到具有更多维数的空间中以进行可靠的比较操作(DCOs)。
实现步骤:
(1)通过随机正交变换对对象进行预处理。(注:这一步仅是随机地旋转对象而不扭曲它们的距离。)
(2)在查询阶段处理不同对象的比较操作(DCOs)时,它会对其转换后的向量进行不同维度的采样。
注:ADSampling 根据查询期间对象的 DCO 自适应地决定每个对象要采样的维度数量,而不是在索引阶段预设一个确定的数量(这需要具有专业知识,实践中难以设置)
ADSampling实现流程
随机向量投影过程
给定一个对象 x,我们首先对 x(向量) 应用一个随机正交矩阵 𝑃' ∈ R 𝐷×𝐷,然后对其上的𝑑行进行采样(为简单起见,使用前𝑑行)。
结果表示为(𝑃' x)|[1,2,…,𝑑]。
我们将转换后的向量表示为 y := 𝑃′x
基于采样的维度,我们可以计算出 x 的近似距离,表示为 dist'

其中 d 是采样的维度数量。值得注意的是,基于采样维度计算近似距离的时间复杂度为 O(d)。
假设检验寻找合适 d
待解决问题:如何确定需要采样多少个 y 的维度,才能对距离比较操作(DCOs)做出足够自信的结论(即是否决定 𝑑𝑖𝑠 ≤ 𝑟)
假设检验的步骤:
(1)定义一个零假设 H0: dis ≤ r 和它的备择假设 H1: dis > r。
(2)使用 𝑑𝑖𝑠′ 作为 𝑑𝑖𝑠 的估计器。

注意:𝑑𝑖𝑠′ 与 𝑑𝑖𝑠 之间的关系由引理 3.1(欧几里得范数存在一个误差概率) 提供(即:𝑑𝑖𝑠′ 与 𝑑𝑖𝑠 之间的差异受到 𝜖·𝑑𝑖𝑠 的限制,且失败概率最多为 2 exp(−𝑐0𝑑𝜖^2))。
(3)设置显著性水平 p(置信区间)

其中,c0 为常数,其中𝜖是一个需要根据经验调整的参数。
(4)我们检查事件是否发生 (如下图公式)。如果发生,我们可以拒绝𝐻0并以足够的置信度得出结论𝐻1: 𝑑𝑖𝑠> 𝑟;否则我们不能。

假设检验的结果:
情况1:我们拒绝假设H0(即我们得出结论 𝑑𝑖𝑠 > 𝑟),且 𝑑 < 𝐷。在这种情况下,时间成本(主要用于评估近似距离)为 𝑂(𝑑),小于计算真实距离的时间成本为 𝑂(𝐷)。
情况2:我们无法拒绝假设且 𝑑 < 𝐷。在这种情况下,我们将继续逐步采样y的一些更多的维度,并进行另一次假设检验。(增加d值)
情况3:𝑑 = 𝐷。在这种情况下,我们已经对 y 的所有维度进行了采样,基于采样向量的近似距离等于真实距离。
因此,我们可以进行精确的 DCOs。我们注意到,具有(可能是顺序的)假设检验的增量维度采样过程的时间成本严格小于 𝑂(𝐷)(当它在 Case 1终止时),并且等于𝑂(𝐷)(当它在 Case 3终止时)。
参数𝜖0:
参数𝜖0 是 ADSampling 算法的一个关键参数,因为它直接控制了准确性和效率之间的权衡(𝜖0 越大意味着假设检验的显著性值越小,这进一步意味着假设检验的结果越准确)。
下图绘制了 HNSW++(左图)和 IVF++(右图)在不同 𝜖0 下的 QPS-recall 曲线。总的来说,我们从图中观察到,𝜖0 越大,QPS -召回曲线就会向右下移动。这是因为较大的 𝜖0 以效率为代价可以获得更好的准确性。
我们观察到,当 𝜖0 = 2.1时,精度损失很小,而进一步增加 𝜖0 则会降低效率。因此,为了提高效率而不损失太多的准确性,我们建议将 𝜖0 设置在2.1左右。

参数Δ𝑑 = 32:
在 ADSampling 中,它增量地对数据向量的一些维度进行采样,并在迭代中执行假设测试。为了避免频繁假设测试的开销,我们在每次迭代中对 Δ𝑑 维度进行采样。默认情况下,我们设置 Δ𝑑= 32。
ADSampling算法流程:
Input : A transformed data vector o′, a transformed queryvector q′and a distance threshold 𝑟
输入:一个经过变换的数据向量 o',一个经过变换的查询向量 q' 和一个距离阈值 𝑟
Output : The result of DCO (i.e., whether 𝑑𝑖𝑠 ≤ 𝑟): 1 meansyes and 0 means no; In case of the result of 1, anexact distance is also returned
输出:DCOs 的结果(即是否 𝑑𝑖𝑠≤𝑟):1表示是,0表示否;如果结果为1,则还返回一个确切的距离
Initialize the number of sampled dimensions 𝑑 to be 0
将采样维度的数量 𝑑 初始化为 0
while 𝑑 < 𝐷 do
Sample some more dimensions 𝑦𝑖incrementally with
逐步采样一些维度𝑦𝑖
𝑦𝑖 = o𝑖′ − q𝑖′
Update 𝑑 and the approximate distance 𝑑𝑖𝑠′accordingly
相应地更新 𝑑 和近似距离 𝑑𝑖𝑠′
Conduct a hypothesis testing with the null hypothesis𝐻0 as 𝑑𝑖𝑠 ≤ 𝑟 based on the approximate distance 𝑑𝑖𝑠′
进行零假设检验,零假设为 𝑑𝑖𝑠 ≤ 𝑟,检验基于近似距离 𝑑𝑖𝑠′。
if 𝐻0 is rejected and 𝑑 < 𝐷 then // Case 1
return 0
else if 𝐻0 is not rejected and 𝑑 < 𝐷 then // Case 2
Continue
else // Case 3
return 1 (and 𝑑𝑖𝑠′) if 𝑑𝑖𝑠′ ≤ 𝑟 and 0 otherwise
注意:当 ADSampling 在 Case 3(即𝑑 = 𝐷)终止时,将不会出现失败,因为在这种情况下,近似距离 𝑑𝑖𝑠′ 等于真实距离 𝑑𝑖𝑠,DCO结果是精确的。当ADSampling在Case 1终止时,如果 𝑑𝑖𝑠 ≤ 𝑟 成立,则会发生失败,因为在这种情况下,它得出了 𝑑𝑖𝑠 > 𝑟(通过拒绝零假设)。
ANN+
ANN+:在运行 AKNN 算法的过程中,每当它进行距离比较操作(DCOs)时,我们使用 ADSampling 方法。
HNSW+:在将新访问的对象的距离与结果集 R 中的最大值进行比较时使用 ADSampling 方法。
IVF+:将候选对象的距离与当前维护的 KNN 集合 K 中的最大值进行比较,以选择生成的候选对象中的最终 KNN 时应用 ADSampling。
ANN++
HNSW++
1、HNSW+:
概念:维护了一个 max-heap 大小为 𝑁(𝑒𝑓)的结果集 R,并将距离作为键,其中 𝑁(𝑒𝑓)>𝐾。对于每个新生成的候选对象,它会检查其距离是否不大于集合 R 中最大距离(的对象),如果是,则将对象插入集合 R。
具体操作:使用 ADSampling 对每个候选对象进行 DCOs,其中 R 中距离最大的对象作为阈值距离。
R集的两个作用:
1、维护了到目前为止生成的候选对象中距离最小的 KNN。这些 KNN 将在算法结束时作为输出返回。
2、维护了到目前为止生成的候选对象中的前 𝑁^(th) ef 个最大距离。这个距离被用作 DCO 的阈值距离,影响候选对象的生成。

具体来说,如果由 HNSW+ 生成的候选对象的距离小于等于 R 中的第 Nef 大距离,则它将被添加到搜索集 S 中进行进一步的候选对象生成。对于每个新生成的候选对象,它会检查其距离是否不大于集合R中最大距离(的对象),如果是,则将对象插入集合R。
2、HNSW++:
概念:通过维护两个集合 R1 和 R2 来解耦 R 的两个作用,即为每个作用维护一个集合。
集合 R 的分解:
集合 R1 的大小为 K,基于精确距离(深绿色)。
集合 R2 具有大小 𝑁𝑒𝑓,并基于距离,这些距离可以是精确的或近似的。
具体来说,对于每个新生成的候选对象,他都会检查它的距离是否小于或等于集合R1中最大距离,并在满足条件时将该候选对象插入到集合 R1 中。
注:这个 DCO 会产生一个副产品,即观察到的距离 𝑑𝑖𝑠'(浅绿色),当 ADSampling 终止时,它可以是精确的(如果所有的 D 个维度都被采样),或者是近似的(如果它以 𝑑<𝐷 的方式终止)。然后,它根据观察到的距离类似于 HNSW+ 维护集合 R2 和集合 S。

总结:HNSW++ 使用的是K作为寻找候选值;HNSW+ 使用 𝑁𝑒𝑓 寻找候选值。其中 𝑁𝑒𝑓 > K。
IVF++
1、IVF:
在原始的 IVF 算法中,同一簇中的向量按顺序存储。在评估它们的距离时,算法按顺序扫描所有这些向量的维度,这展现出强烈的局部性,并因此使其具有良好的缓存性能。
2、IVF+:
它扫描的维度比 IVF 少,但如果使用相同的数据布局,它就无法具有良好的缓存性能。具体来说,当 IVF+ 为数据向量终止维度采样过程时,随后的维度可能已经从主存储器加载到缓存中,尽管它们不是必需的。
3、IVF++:
ADSampling 一定会先采样一些维度(如 𝑑1 个),然后根据假设检验结果逐渐采样更多维度。也就是说,每个候选向量的前 𝑑1 个维度一定会被访问。出于这个原因,我们将所有候选向量的前 𝑑1 个维度顺序存储在一个数组 𝐴1 中,将所有候选向量的其余 𝐷−𝑑1 个维度顺序存储在另一个数组 𝐴2 中。

性能分析(6个数据集)
召回率:成功检索到的真实 knn 的数量与 𝐾 之间的比率。

平均距离比:检索到的 𝐾 对象与真实 knn 的距离比。

结论总结:
结论 1(结果图):
我们可以清楚地观察到 AKNN+ 和 AKNN++ 在达到几乎相同的召回率的情况下,评估的维度比 AKNN 少得多。

具体而言,在 GIST 上,对于 𝑁𝑒𝑓 的所有测试值,HNSW+ 和 HNSW++(相对于 HNSW)的精度损失不超过0.14%,IVF+ 和 IVF++ 的精度损失不超过0.1%。
与此同时,HNSW++ 组在总维度上从39.4%节省到75.3%,HNSW+ 组从34.5%节省到39.4%,IVF+/IVF++ 组从76.5%节省到89.2%。
基线法 HNSW* 从10.9%节省到15.7%,这解释了它在 HNSW 上的改善很小。IVF*/IVF** 可节省28.9%至40.4%。
结论 2:
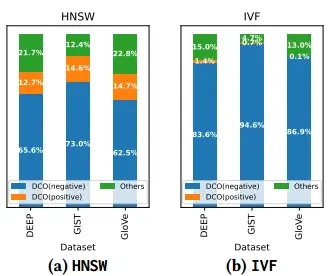
技术在 IVF 上比 HNSW 带来了更多的改进(即使 IVF 比 HNSW 表现更好,例如在 Word2Vec 上)。
原因:HNSW 的 DCOs 以外的其他计算比IVF的计算更重(如下图所示)
结论 3:
该技术总体上在高精度区域比低精度区域带来了更多的改进(例如,GIST 95% vs . 85%)
原因:当 AKNN 算法以更高的精度为目标时,它不可避免地会生成更多低质量的候选对象,并且距离差距更大 𝛼,因此它需要更少的维度来获得可靠的 DCOs。
结论 4:
数据布局优化对 IVF+(即 IVF++ vs . IVF+)的改进大于对 IVF*(即 IVF** vs . IVF*)的改进。
原因:ADSampling 具有对数复杂度,而基线 PDScanning 具有线性复杂度。具体来说,在使用 ADSampling 时,第一个 Δ𝑑 维度对于许多 dco 已经足够,因此可以避免对图4c 中第二个数组 𝐴2 的多次访问。当对 DCOs 使用 PDScanning 时,它仍然会频繁地访问第二个数组,因为它需要的维度超过 Δ𝑑。
补充
索引阶段:
我们首先用 NumPy 库生成一个随机正交变换矩阵,存储它并将变换应用到所有数据向量。然后我们将转换后的向量(AKNN, AKNN* 和 AKNN** 的原始向量)输入到现有的 AKNN 算法中。
对于 HNSW、HNSW+、HNSW++ 和 HNSW*(注意它们具有相同的图结构),我们的实现基于 hnswlib
对于 IVF、IVF+、IVF++、IVF* 和 IVF**(注意它们具有相同的聚类结构),我们的 K-means 聚类实现基于 Faiss 库
查询阶段:
所有算法都是用 c++ 实现的。
对于一个新的查询,我们首先使用特征库[25]转换查询向量,以便在运行 AKNN+ 和 AKNN++ 算法时进行快速矩阵乘法(对于 AKNN, AKNN* 和 AKNN**,它们不涉及转换)。
然后我们将向量输入 AKNN, AKNN+, AKNN++, AKNN* 和 AKNN** 算法。
时间成分分析:
应用 ADSampling 需要随机转换数据和查询向量的额外成本。具体来说,转换数据向量的成本位于索引阶段,并且可以由同一数据库上的所有后续查询摊销。查询向量的转换在查询阶段进行,当出现查询时,查询的代价可以由回答相同查询所涉及的所有 dco 分摊。
为了简单起见,我们将这一步(又称为 Johnson-Lindenstrauss 变换)实现为矩阵乘法运算,它需要 𝑂(𝐷^2) 时间。我们注意到,使用高级算法[19]可以在更短的时间内执行这一步,例如,使用 Kac 's Walk 需要 𝑂(𝐷log𝐷) 时间。
— 参考文献 —
[1]Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence 42, 4 (2020), 824-836. https://doi.org/10.1109/TPAMI.2018.2889473
[2]Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence 33, 1 (2010), 117–128.
向量检索实验室地球号:VectorSearch,关注了解更多
