
Kettle学习笔记(三):常用组件
目前我使用过的组件除了表输入、表输出、插入/更新外还有三类,下面结合实际使用说一下。
一、输入中的excel组件
excel数据应该是日常工作比较常用的类型,因为Office在工作中可以说是无处不在。这次碰到的场景是把excel文件中的内容录入数据库,我以前一般的处理方式是通过excel拼写insert语句,拼装起来是相当的复杂。如果数据量少,我倒是愿意用excel进行insert语句的拼装,因为Kettle的转换设计也需要时间,但是如果数据量比较大,数据字段多,那么设计一个转换流程就相当的方便。
拖入输入中的excel组件,然后右键,选编辑步骤。
1)文件选项卡,可以设置表格引擎,支持excel97-2003、excel2007、openoffice。设置表格引擎后进行文件选择,选择后将文件增加到选中的文件栏。
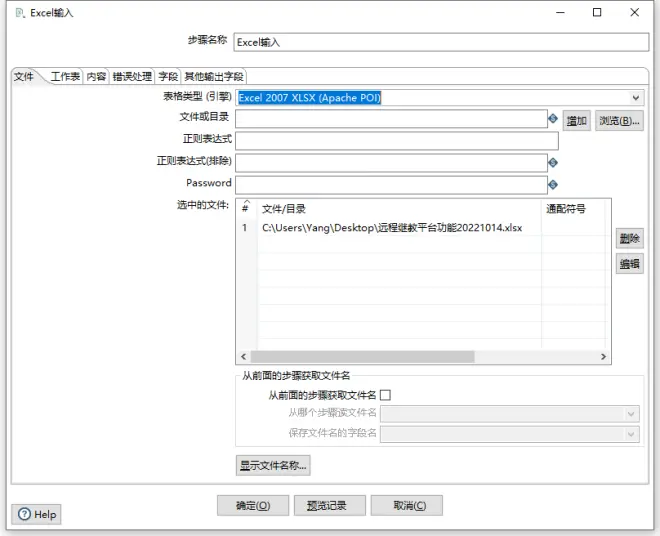
2)工作表选项卡,点击获取工作表名称,在弹出的穿梭框中移动对应的工作簿,然后点击确定。
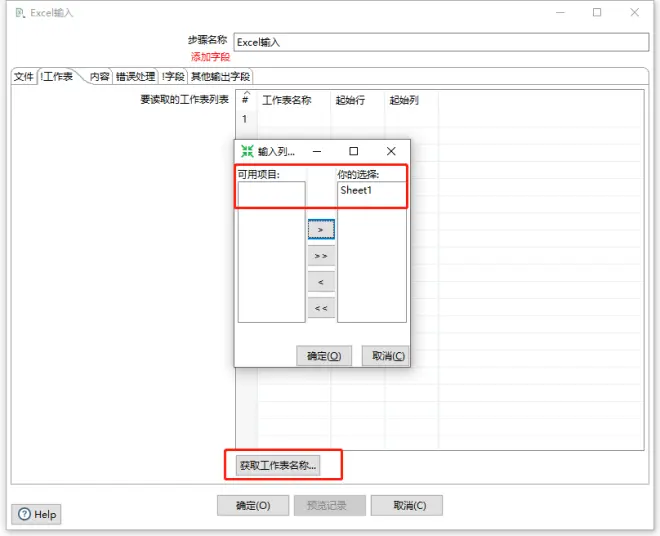
3)字段选项卡,点击获取来自头部数据的字段,可以获取各列的列名。这里需要注意的一点就是,字段类型一定要与数据库中的类型对应,不然后面写入数据库会报错。这里修改字段类型要在原表里进行修改,这里进行转换有可能会出问题。
剩下的内容就是写入数据库了,用之前说过的表输出或者插入/更新都可以。
二、连接中的记录集连接、转换中的计算器和字段选择
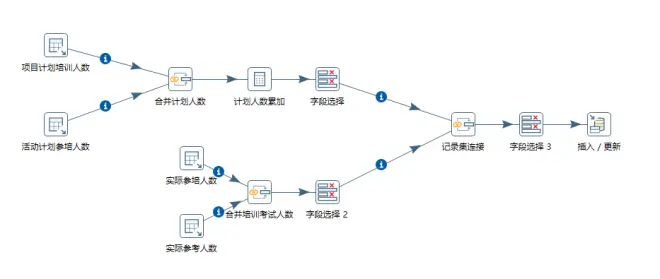
这次的场景是汇总几个业务指标。有一个核心的业务ID,项目和活动是核心业务的两个场景,除了计划培训人数,还有实际培训人数与实际参考人数。我先分别通过两个表输入拿到项目计划培训人数和活动计划培训人数,然后进行记录集连接。连接的方式和数据库的连接方式相同。
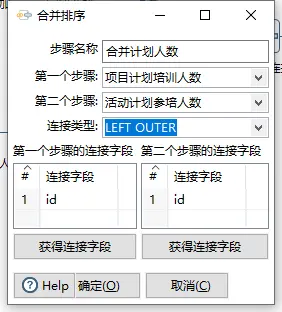
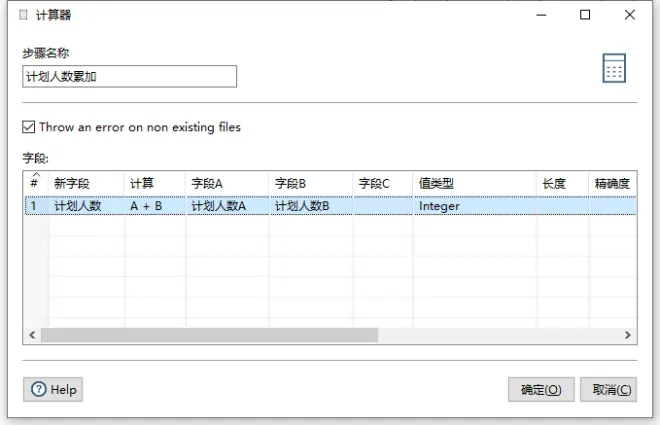
连接成功后进入计算器。在计算器中进行两个数字的累加,生成新的字段。计划人数A和计划人数B是我在第一步表输入中用SQL语句生成的两个别名,方便这里进行计算。
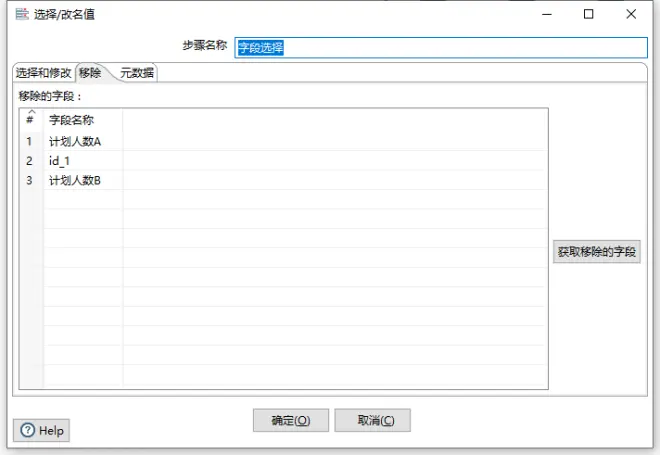
接下来进入字段选择,在计算步骤完成后,在数据流中存在5个字段。id,id_1,计划人数A,计划人数B,计划人数(新增字段)。将其中的id_1,计划人数A,计划人数B移除掉,这样数据流中就只存在id,计划人数两个字段。
到此,三个组件的使用方法已经说完了,后面的其他流程都是这三个组件的重复使用,思路都是一样的。下面是我在第三个字段选择移除完成后保留的我需要的数据。
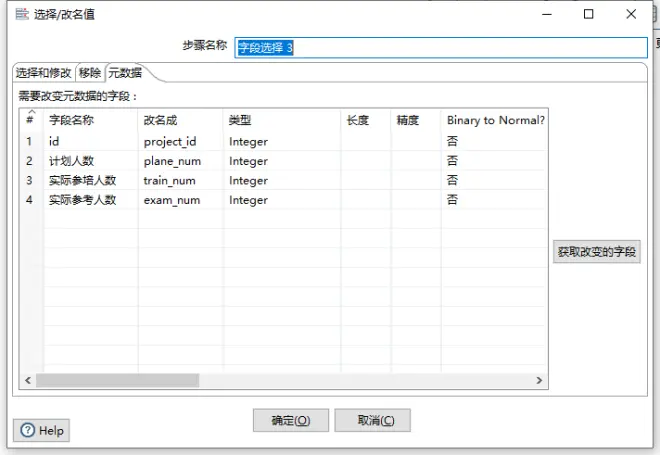
这里说一个我没有解决的问题,在计划人数、参培人数、参考人数合并完成后,我想求参培率(实际参培人数/计划人数)和参考率(实际参考人数/计划人数),但是计划人数有0的情况,我添加了计算器,但是没有找有除0异常的解决办法(可能可以先把为计划人数0的筛选出去再进行计算,待计算完成后再把计划人数为0的合并回来,但是操作太复杂放弃了),后面的参培率和参考率计算是在BI工具中完成的。
三、输入中的生成记录和JSON input、查询中的HTTP client等、脚本中的Java 代码
这部分的场景就是想通过接口获取数据,因为工作太忙,这部分又太复杂的原因,导致还没有做,只是梳理出了一个思路。
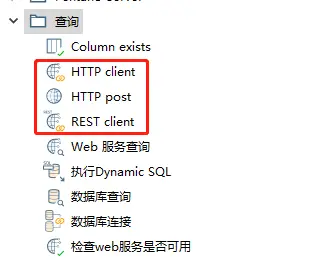
1)先说下查询,查询中有HTTP client、HTTP post、REST client三种,HTTP client就是常见的get请求模式,HTTP post就是post请求,REST client支持多种请求模式。(其实下面还有数据库查询和数据库连接,看起来与表输入类似)

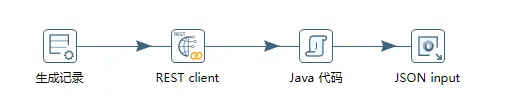
2)说完了查询,说一下为什么一定要生成记录,这是因为Kettle中规定一定要以输入开头。像第二步的查询,它不属于输入,所以需要添加一个生成记录,这个生成记录做什么用呢?在里面添加需要访问的接口地址,然后用REST client去访问这个地址。
3)接下来说一下整体思路。一般接口访问都需要先鉴权,鉴权后第二次再携带权限token再次去接口请求数据才可以请求成功。以上四个组件就是先用生成记录填写目标地址,然后再通过REST client携带鉴权参数访问生成记录中的目标地址,然后返回的结果通过JSON input进行解析。JSON解析后拿到Token,再次发起REST client请求,这次可以直接将目标地址填到REST client的地址栏直接访问,再通过JSON input对返回的结果进行解析,这样就完成了通过接口获取数据的流程。至于为什么需要脚本中的Java 代码,是因为某些步骤可能需要执行Java代码生成一些密钥之类的。整体的思路基本上就是这样,但是由于没有时间的原因一直未真正进行操作。
4)这里要提到一点,就是环境一定要JDK11。我之前使用的是比较新的JDK17,Kettle的开发环境是JDK11,如果使用高版本的JDK会导致语法兼容性错误。
以上三部分就是我这一段时间断断续续对Kettle的使用研究,等后面探索新功能再进行记录。
